
The Challenges of Platform Building on Top of Kubernetes 4/4
TLTR: We have reached a point where the adoption and understanding of Kubernetes and Kubernetes tools are mature enough to start hiding them away from the teams consuming them. This blog post explores some of the approaches different development tools take to provide a better and simplified experience for developers while allowing platform teams to curate the resources these tools use and how they behave.
In the previous three blog posts [1], [2], [3], I’ve focused on the challenges of building platforms on top of Kubernetes. While in this last blog post, I will keep it around Kubernetes, I want to emphasize that hiding Kubernetes from developers is clearly where the industry is going.
I’ve started this series by making sure we place Kubernetes as a critical set of building blocks. The second and third blog posts were about how to use these building blocks to build our company-specific abstractions and use the platform to make these abstractions available to different teams. Now when you think about what we have achieved, for example, creating environments in a declarative way or managing a complex application by using simple Kubernetes resources, we have removed the need for developers to understand how Kubernetes works and how they need to combine concepts like Deployments, Ingresses, Services to achieve what they need. But still, they need to interact with an extended Kubernetes API, as we have seen in the previous blog post, this has its advantages (flexibility to plug new behaviors that can be discovered by interacting with the APIs, an extraordinary ecosystem or tools that you can use, etc.) but how this platform will play nice with the tools that developers are already using?
This blog post is about building the bridge between the abstractions we have made in our clusters and platform and how those abstractions can enable richer developer experiences. This allow our developers to focus on building features instead of needing to understand a complex technology landscape that is forever evolving. The abstractions I will cover in this blog post span from the platforms and the multiple clusters the platform needs to manage to our developers' working stations and their tools.
Developers ecosystem
Unfortunately, there is no single answer to what tools you should promote around developers. Some might want to only code in Java and use their IDEs (or NodeJS and VSCode), and some might want to also create their containers and use kubectl to deploy to their local environments.
But let’s agree on one thing, if you can build features using just your programming language, how you containerize and deploy your application to a cluster just takes time away from working on the next feature. And please don’t get me wrong, tools like docker and kubectl are essential when you are trying to build what I call “standard and modern distributed applications” (distributed feel much more concrete than Cloud Native or just Cloud). Suppose you, as a developer, learn how to use tools like Docker for containers and kubectl to interact with Kubernetes. In that case, you immediately align with how to deploy workloads in all major cloud providers. And that is a significant advantage, now you can change jobs, and your knowledge of the tools that you have learned to use will be helpful no matter which other cloud provider the new company has decided to use.
But this knowledge comes with the downside, you need to invest time to acquire it. Let's be real, it is not just a training course or certification away. Things like creating secure and lightweight container images take not only time but also experience. You need to mess up with things several times to learn some hard lessons. If you transpose that to a large team new to the cloud space, you will need to find a way around these time and expertise limitations.
Let’s analyze some developer tools and how the platform and the platform team can assist developers in being more efficient by automating tasks and providing guidelines and best practices whenever possible:
- Projects, Dependencies and quickstarts
- Projects and dependencies: Can the platform team and the platform itself promote project templates and curated dependencies for developers to rely on? Two standard practices that platform teams can implement are project quickstarts and curated dependencies:
- Project Quickstarts are just "project templates" that teams can use to start new projects. Sometimes mechanism to upgrade from a new version of the template is also provided. These templates can include company-curated dependencies, for example, a specific version of a driver to connect to a particular instance of a database, custom company-wide helpers and utilities, or even default configuration files, so developers don't need to spend time getting started.
- Curated Dependencies: depending on the tech stack that the teams are using, the platform team can define which libraries (and their versions) can use to perform different tasks. Sometimes it makes sense to wrap all these dependencies into bundles that development teams can import into their projects. This hides away from the teams the complexity of understanding tools that will impact the entire application and not only the project they are working on, topics such as logging, tracing, metrics, and security tend to fall into this category.
- A third (and a more Cloud Native) approach is to push some of these concerns down to the infrastructure / Kubernetes layer. Tools like Knative, Dapr, and even service meshes try to remove the burden of including dependencies on your services for platform cross-cutting concerns. Tools like this, which work on top of Kubernetes can make the development experience less painful, as developers can focus on building features using well know and supported protocols like
HTTPand grpc, using the language of their choice.
- Projects and dependencies: Can the platform team and the platform itself promote project templates and curated dependencies for developers to rely on? Two standard practices that platform teams can implement are project quickstarts and curated dependencies:

- Tools
- IDEs (Integrated Development Environments): some teams like to use full-blown IDEs such as IntelliJ Idea, Netbeans, Eclipse, but others can use simple text editors without too many plugins to work. Understanding your teams' preferences can help you distribute configurations for their tools to save time and promote good practices. Simple things like linters, code validations, and configurations for their IDEs to access private plugin repositories might help get new team members started working on their projects.
- Configurations: depending on the editors that developers are using, platform teams can promote the use of standardized configuration for code formatting, licenses, plugins that they can use and services that they can use such as accounts to access code repositories or documentation. A promising space that aims to enable platform teams to standardize the whole IDE/editors ecosystem is the fully remote IDE experience with tools such as GitPod, Github Codespaces, and others trying to get into this space. This might be worth exploring with small teams to see if they face challenges before pushing this to an entire organization.
- CLIs (Command-line interfaces): command-line tools had been around forever, but with the rise of Kubernetes tools like
kubectlanddockerbecame very popular among developers. If you have used the Google Cloud Platform thegcloudcommand line tool is a must-have. But managing and keeping all these CLIs (usually clients to a service provider) up to date can become quite challenging. I haven't done much research on this topic but in the same way that Google Cloud Platform manage theirgcloudCLI (its dependencies and versions), your platform will need to have a way to distribute and check that the correct CLI versions are being used. - Package Repositories (Containers, Dependencies): If developers are producing containers of binary packages, they need to have a secure place to store them. In the same way, if they are consuming third-party dependencies, these dependencies will need to be cached in an internal proxy to avoid the entire organization downloading these binaries every time they perform a build.
- Source Code Repositories: the larger the organization, the more difficult it is to find where things are. Having a registry containing links to where the source code for different services live, where shared code can be stored for other teams to use, and the steps to build these projects locally become part of the services that a platform should offer. Helping teams to navigate a complex organization can save more time than adopting the latest and greatest new web framework.
- Accounts: once you find what you are looking for, you need to be able to access it. Or, it can also be the other way around, that you cannot find what you are looking for because you are not signed in to the right system. Having single sign-on for all the services related to the platform is vital to avoid people getting frustrated because they cannot access to shared resources.
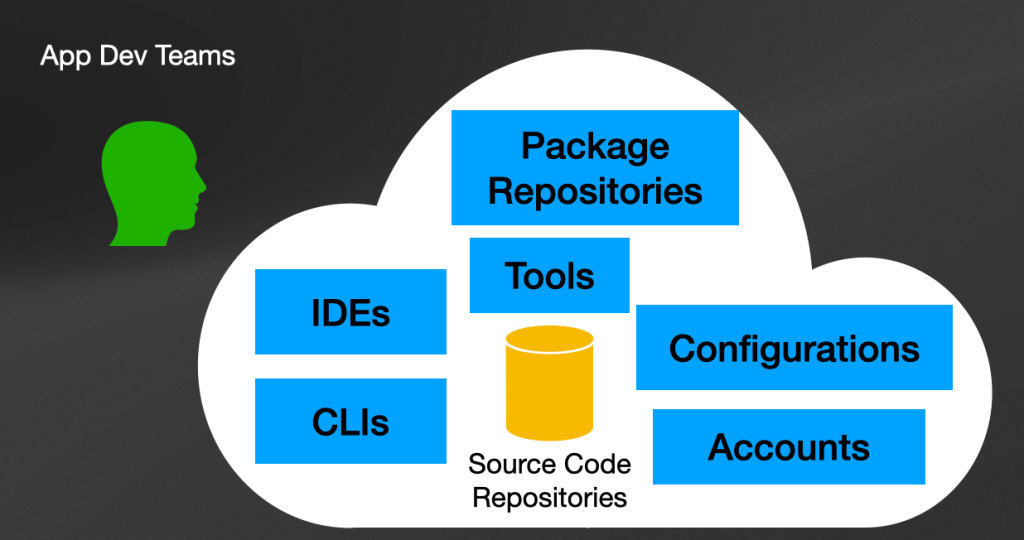
- Environments
- We talk about provisioning tools and infrastructure for development teams to be ready to do their work. Knowing your teams and the tasks they will be performing is key to building a useful platform. But besides infrastructure (cloud resources, clusters, and tools installed on those clusters), what other aspects should we consider?
- Data: do your teams need mock data to test their changes? Application development teams shouldn't be in charge of creating or installing these data sets. You can save enormous time by having a process to define which data might be needed to perform specific tasks. Then if you are creating environments for your developers, these datasets can be automatically provisioned, saving them time to focus on coding instead of dataset creation.
- Security: what kind of security mechanisms will your developers need to have set up in their development environments? Do they need encryption and TLS enabled for their development tasks? Does this needs to be enabled at the infrastructure level, or can these configurations be left out for development purposes because production and other environments will take care of this? Can specific security roles (RBAC) be configured for your development environments? Do applications need to use a particular
ServiceAccountto run? Having these settings baked in helps developers know how the application will behave outside their development environments and can influence how they design solutions. - Users/Groups: what kind of identity management solution are your applications using? what users and groups need to be pre-populated for development environments? and how it would be to change them? Can you connect your development environments to a centralized identity management solution configured for development purposes? Users and groups can be considered data or configurations. Hence the cost of pushing developers to configure these tools is high. I've seen teams spend enormous amounts of time doing reverse engineering on which groups and users are needed to run services or access a particular feature. Look for tools that provide import/export of users and groups to different instances, so the platform team can version and distribute these configurations to different environments.
- Application Flags/Parameters: developers have learned to configure their services and applications using environment variables by using containers. Teams also use feature flags to customize their application's behavior or to enable/disable different features. It is vital to ensure that development environments can import setups that mimic how the applications are being executed in other environments. The platform team will need mechanisms to distribute and install these configurations, so developers have not only an environment but the application ready and configured in a way that they don't need to worry about that.
- We talk about provisioning tools and infrastructure for development teams to be ready to do their work. Knowing your teams and the tasks they will be performing is key to building a useful platform. But besides infrastructure (cloud resources, clusters, and tools installed on those clusters), what other aspects should we consider?
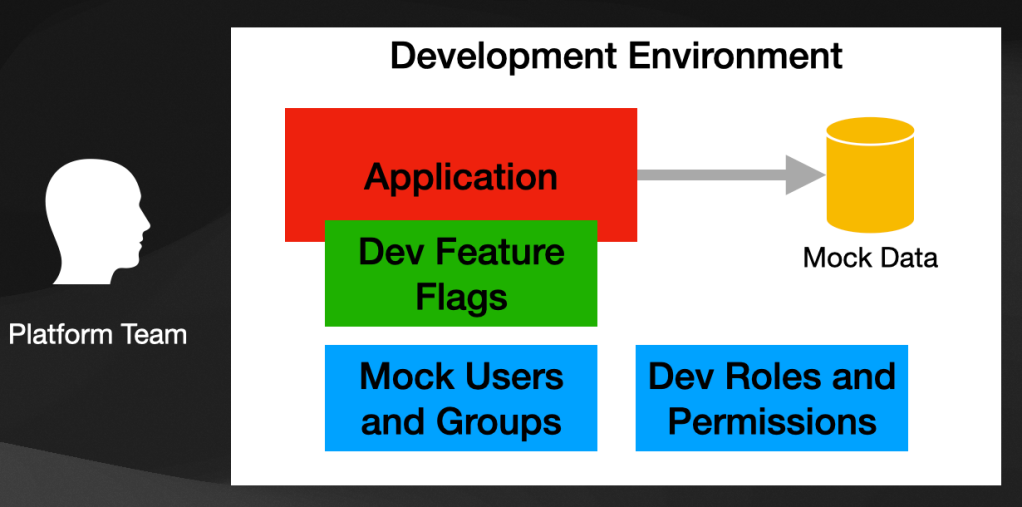
It is your job as a Platform engineer to evaluate the tools you are adopting to see how easily they can integrate with other tools and externalize and version their configurations so new environments can easily be bootstrapped. If the tools you adopt don't provide this level of flexibility, the platform team will pay the price of writing a lot of glue code and automation. Otherwise, development teams will waste an enormous amount of time trying to figure out all these details.
As you can see, there are a lot of aspects to cover from a platform perspective. I would recommend describing and explaining all these aspects to the main stakeholders that will invest resources in the platform and platform team(s).
But what is the optimal experience that we should aim for?
The mother of developer experiences
I would argue that the holy grail of experiences must be the one that allows development teams to push straight to production. You are a developer, and you are tasked to implement a new feature or fix a bug. You have written the feature and tests, you have pushed them to the source code version control system, and the CI pipelines are happy with your changes. Now, the company goal is to get those changes in front of live users as soon as possible. The platform's responsibility is to assist both development teams and the organization in making this happen.
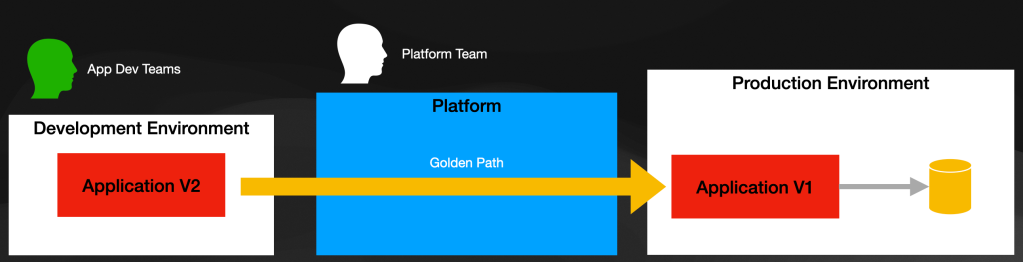
I do see two main phases involved in this process:
- Inner developer cycle: developers are making changes and want to iterate fast and test how their changes are behaving. For this, usually, a small and ephemeral environment will do. You want to run your code as quickly as possible to test your assumptions and make progress. Sometimes you might need some other services or data to build a particular feature and see it working.
- Paths to Production: (golden paths) developers are happy with their changes and have tests to back up that their changes are doing what they were supposed to. From then on, automation and feedback should be the kings. You want their changes to flow toward the production environment, and if something goes wrong along the way, the platform should let them know why, so they can fix any issues.
Phase #1: Inner Developer Cycle
For the Inner Developer Cycle, you want to enable developers to use the tools of their choice so they can iterate fast. There is a debate about cloud development environments and whether you need Kubernetes for development tasks. I am a big supporter of making sure that the way that the developer runs software mimics how that software will run in production as close as possible. So it is all about what kind of software you are trying to build. If you are building “modern and standard distributed applications” following container best practices and leveraging the Kubernetes scaling and self-healing features, this influence how you code and architect your applications.
Suppose you let your developers do their work with their tools of choice and help them deploy and test their changes into Kubernetes. In that case, you rip the benefits of developing environments that behave more closely to production. How would you do that without pushing every developer to learn how to create containers and all the Kubernetes concepts they might need? Also, you need to ensure they do not spend time figuring out how to create Kubernetes clusters. As we have seen in previous blog posts, that is the Platform's task. To recap, you want Kubernetes and containers involved in the development cycle but don’t want developers spending time learning or using them. What can the platform and platform team do about that?
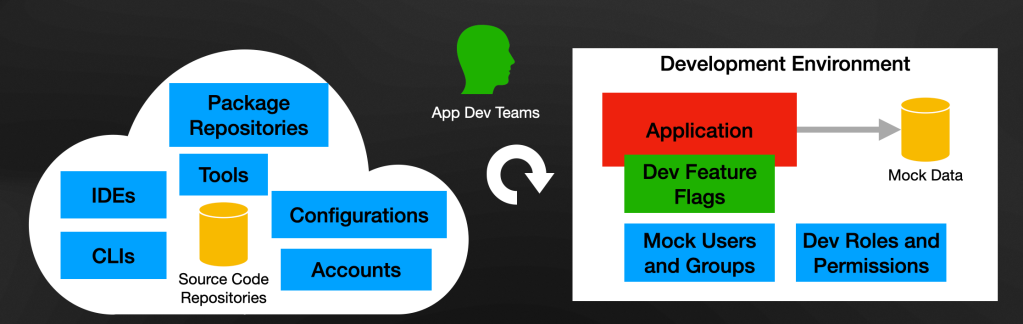
Later in this blog post, we will try to answer this question with an example.
Phase #2: Paths to Production
Let’s quickly discuss the challenges we face when building our Paths to Production. Promotions to production are complex and very industry and company-specific. Hundreds of tools and many manual approvals might be required to move code from development to our production environment(s) where the application will be accessed by real users. If you are working with Kubernetes and following the Kubernetes ecosystem, you might have heard about GitOps and Infrastructure as Code. These two approaches make a lot of sense in managing more sensitive environments.
Using an Infrastructure as a Code (IaaC) approach, you version the configurations of these sensitive environments using Git so you can easily recreate or create copies of these environments by applying these configurations. Suppose you use a GitOps approach to sync your application configuration changes to these environments. In that case, you can focus on managing the changes instead of managing the clusters and infrastructure required by your application. The challenge shifts from who has access to which environment to who has access to which Git repositories to make changes to promote the latest application version to that environment.
While IaaC and GitOps are excellent steps forward to automate complex infrastructure and manage application changes in an automated way, what’s missing is the very domain-specific validations, governance, and policies that need to be checked to ensure that the changes that are being promoted are going to work. In other words, the path to production doesn’t end when you land the changes to the production environment, and users can access the new functionality. It ends when your changes are guaranteed not to break or degrade your application’s performance. This is precisely where tools that offer automatic remediation mechanisms (for example, Keptn) and constant monitoring of environments are essential to ensure that we can quickly revert back to a good and stable state when things go wrong.
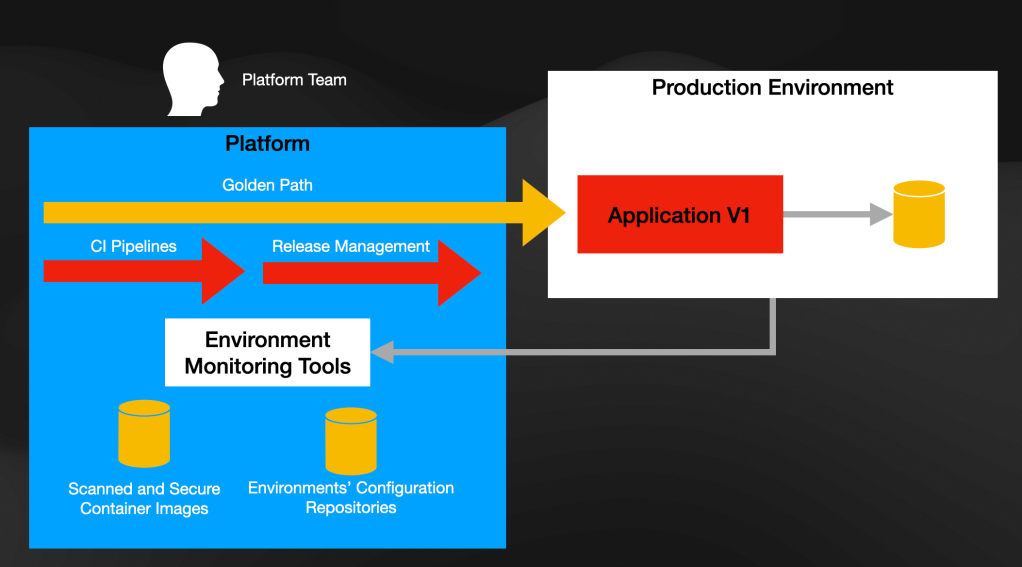
But let’s get back to the topic of this blog post. How does all of this tie back to developer experience? From the Paths to Production perspective, the platform needs to provide constant feedback to teams about where their changes are and if there were any incidents related to the changes. If you tie this back with GitOps, you will now have a Pull Request in a Git repository which is in charge of testing and validating the required configuration changes to include your changes in the production environment.
Both phases combined
If we try to summarize how all these tools should work together to provide a developer experience that is focused on improving our developers' performance, this is how it should work:
- Requesting an Environment to work: Development team requests a new environment to work on a change by interacting with the Platform APIs or the Platform Portal.
- Environment details: The Platform provision a new environment and provides credentials to the development team to connect and work with it. The environment has the tools that the team needs to work (inside it). This can include other services, mock data, etc. The Platform has encoded all these details behind the Platform APIs.
- Connecting to the environment: The development team then connects to the new development environment. If the environment is a Kubernetes cluster or not shouldn’t be a concern for the team. Once they are connected to the environment, they should be able to use their tools of choice to build and deploy their changes. Tools, such as the ones we will see in the next section, can further abstract the technical details of the environments and work with conventions to ensure that developers can focus on writing features that provide business value.
- Validating changes: Once the changes are made, and the developer tests these changes with unit tests and works on the development environment that the Platform provisioned, a Pull Request will be sent to the source code repository where the project lives. At that point, Continuous Integration pipelines will verify the changes (performance, correctness, integration tests, regressions, etc.), and when all verifications are done, the change will be approved.
- Keeping track of releases/changes: If the organization uses a trunk-based development approach, merging a new change will create a new release for our application/service. This can be the trigger for the platform to know that there are new candidates to be promoted to more sensitive environments. From here on, the platform is responsible for keeping the development team up to date with what is going on with their changes. After releases are created teams like QA and AUT can happen and report back their findings.
- Promoting a release to production: when the organization is ready to promote a change (or a batch of changes) in front of all the users, a promotion process should begin. This process can be as complex as the organization needs, including manual validations and automated tests. The process can use a GitOps and automated approach to track all the steps that need to be performed. If using a GitOps approach, this usually means a Pull Request to the repository that contains the changes in configurations to promote the new version(s) being promoted.
While the Platform is directly responsible for Validating changes and providing feedback to development teams while Keeping track of release/changes, the platform also directly influences how developers do the work while interacting with platform-provisioned environments.
In the next section, we will look at a concrete example of a tool that primarily focuses on the developer's inner cycle. Still, it also helps the platform team to build paths to production while promoting best practices and a very concrete developer experience.
Example: Knative and Knative Functions
Building developer experiences is challenging. Building good developer experiences is more complex and takes time and iterations. After working for almost. a year with Knative Functions, and for more than 6 years in the Kubernetes space, I've learned to appreciate and recognize tools that bring different aspects together to build a cohesive developer experience. While Knative Functions is a young project and it is in no way perfect, it brings most of the topics that I've discussed in this series of blog posts together into a simple developer experience. This developer experience is limited to building functions. While functions might not work for everyone, I hope the developer experience described in this section inspires other projects to build upon.
Check the official documentation and getting started tutorial here: https://knative.dev/docs/functions/
The premise is simple, with Knative Functions, you can create, build, run and deploy functions. These functions can be written in any programming language. Knative Functions will transform the source code of your functions into a container image without pushing the developer to learn docker or how to create container images. Knative Functions is also in charge of publishing this container image so it can be deployed to a remote cluster, without pushing the developer to write any YAML file.
But you might be wondering what Knative Functions is? How do I install it? or how many things do I need to install and configure for this to work? And these are all fair questions. To put it simply, Knative Functions is a CLI (Command Line Interface) that is the entry point to a developer experience that enables developers to focus on writing functions. Besides the CLI, which targets existing users who are already familiar with Kubernetes and kubectl, Knative Functions also provide IDEs plugins for IntelliJ and VS Code.
While you can use Knative Functions to create and run functions without having a Kubernetes Cluster, the real power of Knative Functions materializes when you deploy your functions into a Kubernetes Cluster that has Knative Serving installed to serve as the functions' runtime.
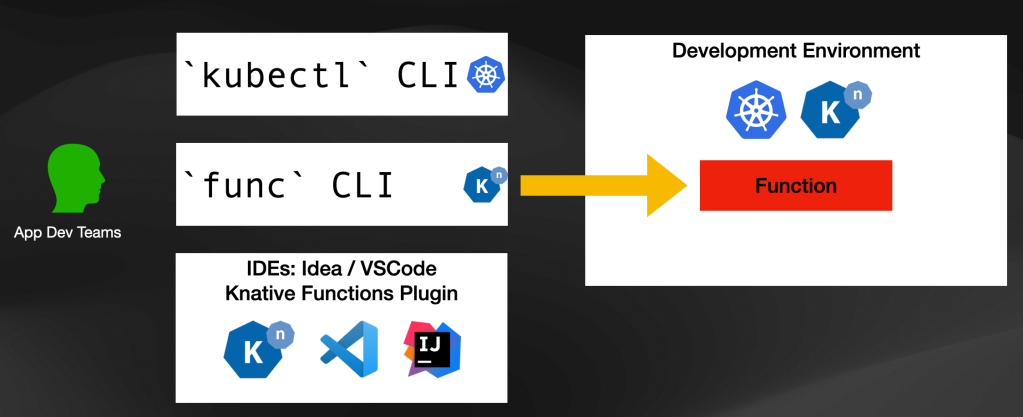
Before going into the runtime part of functions, let's analyze the inner developer cycle proposed by Knative Functions. We will pay special attention to how Knative Functions was designed to fit very nicely into our platform story.
Let's start by looking at function creation, as developers are supposed to create, build and run functions in their workstations.
Creating Functions
By running func create (or the equivalent option in the IDEs plugins) developers can create a new function project structure.
The func create command accepts several parameters but let's take a look at arguably the most critical three parameters:
- Language selection
"-l": you need to select which programming language you want to use to create your function. Supported languages today are Go, Node, Python, Rust, TypeScript, Java (Spring Boot and Quarkus). If the language you want to use is not in this list, don't worry, new language packs can be added by design. - Template selection
"-t" : this is optional, but once you have selected a language you can choose to create different project structures depending on what the function is going to do. For example, if you know that your function will need to connect to a database, you can have a template that makes that process easier for developers. The same can apply if we connect with a legacy system requiring special libraries. - Template repositories "
-r": by selecting a different template repository, you can build. your organization's internal library of supported templates and language packs.
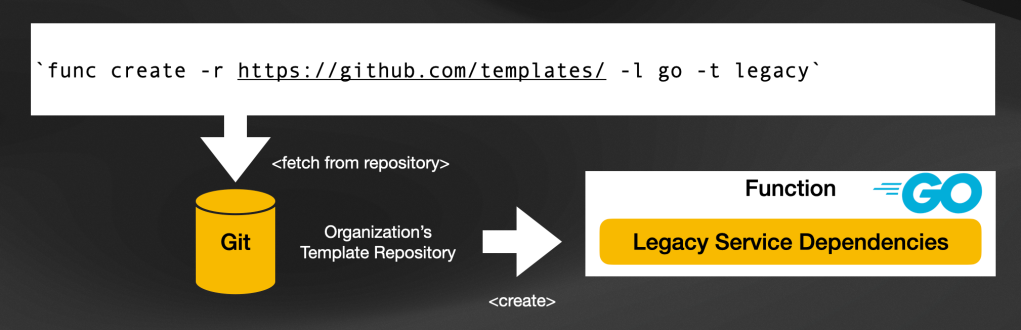
Platform teams can curate templates and language packs that developers use to create functions, including platform-wide decisions such as company-wide libraries, framework selections, and best practices.
Once the function is created, developers will want to build and run these functions. Let's take a look at the next phase: Building functions.
Building Functions
No matter which language you are using you want to be able to build and run your functions. Because, eventually, we will want to run these functions into a Kubernetes Cluster, the building process will also include creating a container image.
When using func build, Knative Functions take care of doing all the heavy lifting for you. Knative Functions was designed to support a pluggable building mechanism, nowadays, it supports S2I (for Red Hat's Openshift) and CNCF Buildpacks. Both of these builders evaluate your source code and then automate the creation of a container image.
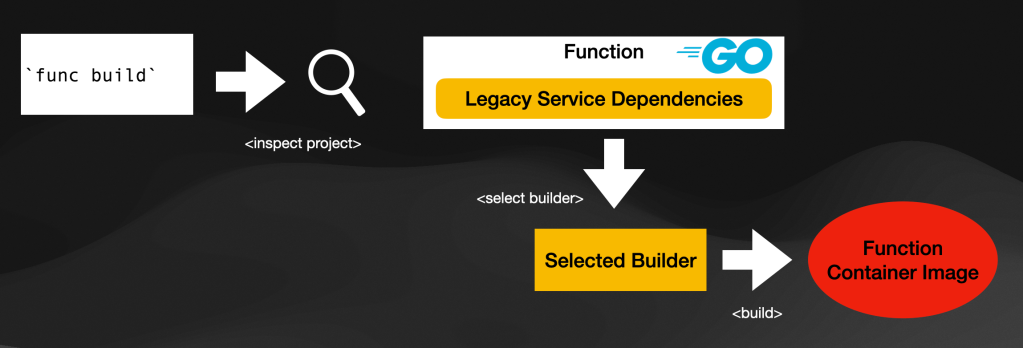
By using func build, Knative Functions is trying to abstract away the complexity of creating container images from developers. More importantly, allow Platform Engineers to define how that process works by allowing them to create their own custom builders. This is extremely important from an organizational point of view, as developers creating and defining how containers are created tend to lead to security issues and a lack of company governance. Creating Dockerfiles is not something that developers should be spending their time on, as it is something that looks simple to get something running, but it will require a lot of hardening by someone who has the right expertise and understand the organization's requirements.
It is crucial to notice that func build, by default, try to push the container image to a container registry. If you are working locally you can skip this by using the --build false argument.
The trained eye might have noticed that the building process does require to have Docker or similar installed locally to perform the build. While this is possible for some organizations, for others this might be a blocker. Knative Functions does support also a remote building option, that I will briefly discuss in the following sections. This remote build, open the door for more constrain environments, once again, enabling platform teams to reduce the amount of tooling that developers need to know and have installed in their workstations.
Once the function container image is built, you can run it locally.
Running functions
Running is simple. If we have a container image, we just need to start it and ensure we can forward traffic to it. func run requires you to install docker, as it will start the container image we just built.
The idea behind func run is to run the function as close as it will run in Kubernetes. func run does an automatic port-fowarding to, once again, prevent developers from understanding too many details about containers. The idea here is to give developers an URL where they can contact the function to manually test and see if it is working.
Once you are happy with your function, you need to start thinking about where this function is going to run so your customers can access the new functionality.

Deploying Functions
Knative Functions leverage Knative Serving to provide a true "serverless" approach and deployment model on top of Kubernetes. The idea is to deploy our functions and leverage Knative Serving scaling capabilities to automatically scale (and downscale) our functions instances based on demand. Because Knative Serving was built and designed as a Kubernetes extension, you can use all the excellent tools in the Kubernetes ecosystem to monitor and manage the functions that you will. be deploying.
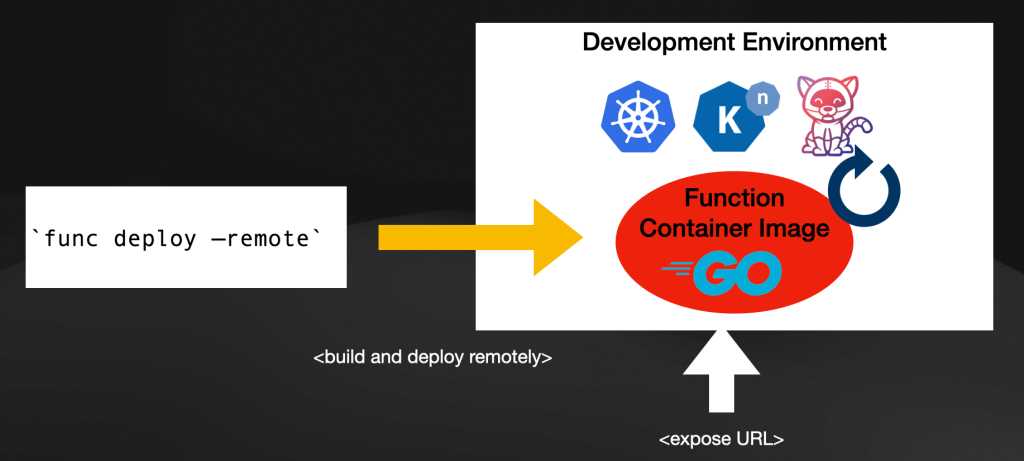
By using func deploy developers can deploy their functions to a Kubernetes Cluster, in a way where they don't need to understand how all the process works. func deploy uses the credentials configured in your local environment to connect and deploy functions without pushing developers to write any YAML Kubernetes resources.
Once again, for this step to work you, as a developer, need to have access to a Kubernetes Cluster that has Knative installed on it. If your platform team helped you to provision a new environment and gave your the credentials to access that environment, func deploy should just work.

From a developer experience perspective, func deploy is the only command you need to build, push and deploy your function. This greatly reduces the cognitive load from developers who only need to run a single command to see the latest version of their functions running in a Kubernetes Cluster.
One key aspect of the Knative Functions project is that now that the initial experience is well defined, the project is starting to evaluate other builders and deployment runtimes. Having a WASM builder might enable very popular communities to write functions using the WASM tech stack. On the runtime side, it makes a lot of sense to leverage other frameworks and tools, such as Dapr, can improve even further the experience.
Functions Paths to Production and Platform integrations
So far, with func deploy developers can get their functions (no matter the programming language) into Kubernetes quickly and without creating Dockerfiles or writing YAML files. But how does this work when they have finished their changes and they want to promote their functions to their production environment? should they be using func deploy for that too?
To integrate tools like Knative Functions into our platform and build our golden paths, I wanted to cover two topics:
- On-Cluster builds
- Knative Functions and GitOps
With On-Cluster builds, you can further remove the need for having a Docker daemon running in every developer workstation. The idea here is to trigger remote builds that run in a remote environment. For such scenarios, the platform will need to provide these capabilities. Currently, Knative Functions supports Tekton pipelines for remote builds. This means that as soon as the target cluster has Tekton installed, Knative Functions can trigger a remote build (and deploy) that will all happens remotely. At the end of running the pipeline, the function URL will be returned to the user.
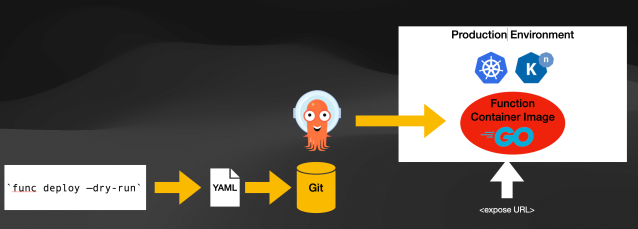
When talking about GiOps, the good thing is that a Knative Function is just a Knative Service. Hence this resource can be stored in a Git repository for tools like ArgoCD to sync into a live cluster. There is currently an open issue to improving the func CLI to export the YAML resources instead of directly applying them to the target cluster. If you can run func build or func deploy with a flag like --dry-run and get the YAML resources for Knative Services and Tekton Pipelines, you could use these commands as part of your CI or CD pipelines.
Sum up
In this long blog post, I've tried to show examples of the importance of choosing tools that enable our platform engineering teams to provide tailored developer experiences. While I've used a function-based approach to demonstrate some of these concepts, other developer experiences can reuse similar mechanisms to enable platform teams to help developers to be more efficient in delivering software.
In this series titled "Challenges of building platforms on top of Kubernetes," I've tried to cover the most essential topics for someone with a development background. I will be very interested in collaborating with people from different backgrounds to understand how the technical challenges can be combined with cultural changes inside organizations that can facilitate the adoption of these practices and approaches.
I will write one more blog post on the subject to cover the importance of measuring these platforms to ensure that all the investments can be justified. Platforms cannot only work in the technical realm, they need to improve how software is delivered. This needs to be backed up by factual data that the organization can use to justify new initiatives and investments.
Drop me a message on Twitter: @salaboy or Mastodon: @salaboy@hachyderm.io if you want to chat or if you think I should also be covering some other angles about platform building, Kubernetes, development tooling, or something else cloud-native related.
Thanks for reading!