
Dapr and Knative Functions
Yesterday I finished my second week at Diagrid.io, and I couldn’t be more excited about what is coming for 2023. In these first two weeks, I started experimenting with Dapr.io, a project that I was aware of but I’ve never used before, and oh boy… it is good, and it aligns perfectly with the tools that I’ve been working on so far.
In this blog post, I am sharing my initial exploration from my Knative Functions background and how Dapr can hugely improve the function developer experience, always promoting a polyglot environment.
For me, Dapr makes total sense mostly because I’ve worked and contributed with Spring Cloud before, which for the Java community was targeting the same, or very similar developer concerns. Dapr takes some of the patterns implemented by Spring Cloud and makes them available to all programming languages by implementing a sidecar pattern. Still, as we will see in this blog post, other patterns might also work.
This blog post is divided into three sections:
- Dapr, my preconceptions and wrong assumptions
- “Dapr”izing a Knative Function
- Current limitations and possible extensions
Let’s start with some of my preconceptions about Dapr and some background.
Dapr
I’ve always had this preconceived notion of Dapr competing with Knative in some way. Both projects are in the same space but come from different angles. Let’s analyze this to put things in perspective.
For me, Dapr was always about the Actors model and a project heavily promoted by Microsoft, hence more closely related to the .NET framework and the C# programming language. Because I’ve never had the chance to dig into the “Actors model” for concurrent computation or the .NET framework, I felt that Dapr would take too much of an investment for me to get started with.
Today in 2022, because Dapr is part of the CNCF ecosystem and heavily aligned with Kubernetes, none of these preconceptions apply anymore. While Microsoft is still one of the project contributors, a very vibrant community of adopters from all over the world and companies like Diagrid are ensuring the project thrives.
Here are some stats from the project from OSSInsight.io


So what is Dapr? Dapr is a set of building blocks (each providing an API) to enable developers to build distributed applications. These building blocks aim to implement common patterns that, sooner or later, you will need if you are building medium/large-size applications. On top of this, Dapr makes these building blocks available to all programming languages. Dapr does this by exposing different APIs for each building block that is local to the application. For example, if you want to read or store state, you only need to send a request to <LOCALHOST>:<DAPR_PORT>/v1.0/state
Dapr also focuses on developer experience by having well-defined developer workflows as well as it integrates well with Kubernetes for local and remote development workflows.
So let’s quickly look at the building blocks (components) offered by Dapr:
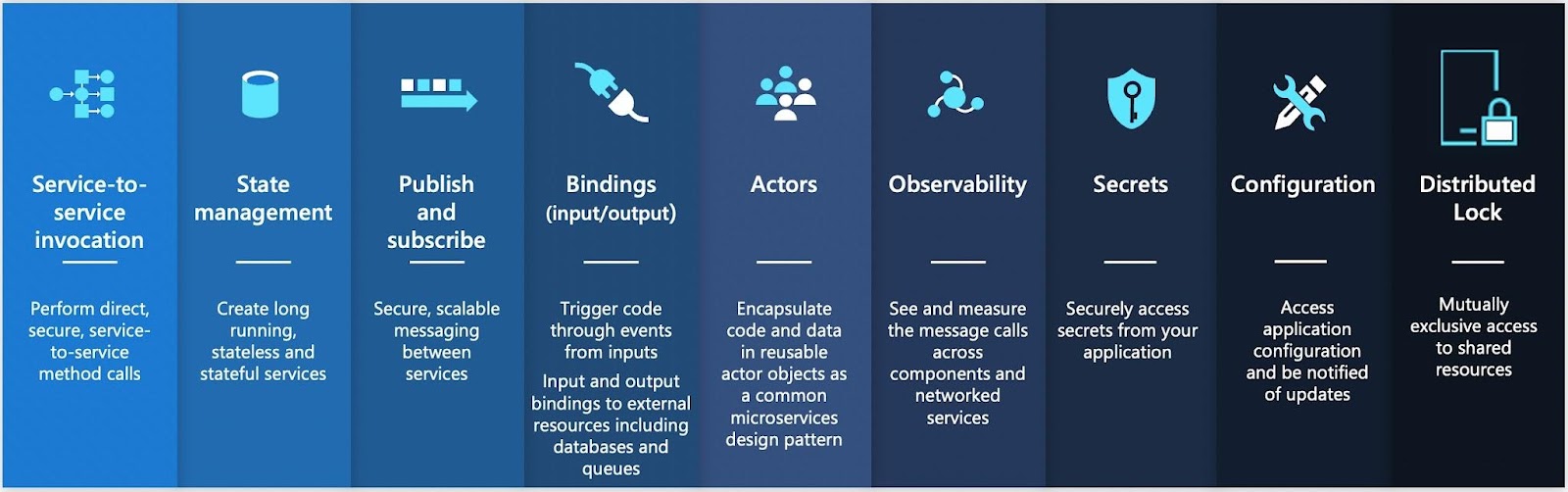
For this blog post, I will focus on State Management and Observability
- State management: storing state is part of every application and the primary mission of the state management building block is to provide an API to store state without making developers worry about where that state is going to be stored. By working with an API instead of database drivers, developers can focus on storing and consuming data instead of spending time figuring out how to store it or from where to read it.
- Observability: if you are running distributed applications you need to have a way to understand what is going on when things go wrong. Dapr allows you to configure in a declarative way how tracing, metrics, and logs are collected.
(Coming soon) Workflows: I am excited to see workflows coming into Dapr 1.10, as this provides higher-level constructs for the orchestration and coordination of different services and events using a declarative way.
Let's look at how we can use these building blocks with Knative Functions.
Dapr and Knative Functions
I have some other blog posts about Knative Functions, the `func` CLI, and how they enable developers to create functions in any programming language (can use templates) and deploy them into Kubernetes without the need to write Dockerfiles or YAML files.
With Dapr, we can enable these functions to, for example, store and read state into a persistent store without the need to directly connect to it or use a special library to connect with it.
In the example and step-by-step tutorial, we will extend a monolith application with a function that will add new functionality. This new functionality must connect to persistent storage and read some data to perform calculations. This is where Dapr and the State Management building block highly simplify how the developer obtains this data.

The monolith application creates values on the client side (browser) and sends the data to the backend, which connects to Redis for this example and stores the values in an array. The client-side also goes to the backend to retrieve all the available data from Redis by performing a query.
If we want to create a function to calculate the average of all the stored values, we can create a new function using Knative Functions.
You can find the step-by-step tutorial here: https://github.com/salaboy/from-monolith-to-k8s/blob/main/dapr/README.md
At the end of the tutorial, you should be able to enable your users to calculate the average of all the values by calling a function from your application user interface:

I will create a video for this demo when I return from my holidays.
Current Limitations and possible extensions
It is pretty easy to “Dapr”ize a Knative Function, as we only need to add four annotations to our func.yaml file:
…
deploy:
…
annotations:
dapr.io/app-id: avg
dapr.io/app-port: "8080"
dapr.io/enabled: "true"
dapr.io/metrics-port: "9099"
If you have Dapr installed in your cluster, these annotations will let Dapr know that it needs to inject the sidecar, which enables the application to connect to the Dapr components.
Then from inside the function, you can use the Dapr Client (a library provided in several languages) that allows you to easily connect to the components removing a lot of boilerplate. If you want to avoid using a library altogether, that’s not a problem at all, you can use plain HTTP requests to interact with Dapr components.
For this very simple application, this code was needed to connect to the state store and retrieve data from it:
daprClient, err := dapr.NewClient()
if err != nil {
panic(err)
}
result, err := daprClient.GetState(ctx, STATE_STORE_NAME, "values", nil)
Where STATE_STORE_NAME is the name of the State Store Component that we defined in our cluster:
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: statestore
spec:
type: state.redis
version: v1
metadata:
- name: keyPrefix
value: name
- name: redisHost
value: redis-master:6379
- name: redisPassword
secretKeyRef:
name: redis
key: redis-password
scopes:
- webapp
- avg
auth:
secretStore: kubernetes
The really important thing here is the APIs and protocols that we have used here. In our function code, there is no reference or dependency on Redis. Dapr is abstracting away the persistent store, allowing us, or the platform team, to replace the persistent storage with any other storage supported by the Dapr APIs without the need to change the function code.
The step-by-step tutorial also configures tracing, metrics collection with Prometheus, and log aggregation.
For tracing to work, you only need to add an extra annotation to the function (func.yaml): dapr.io/config: tracing and configure the tracing stack (Zipkin in this case).
To get metrics working the process is very similar, you configure the metrics collection stack (Prometheus) and then add another annotation: dapr.io/enable-metrics: "true". But in this case, because we have changed the default port for Prometheus to scrap metrics, we also need three Prometheus annotations:
prometheus.io/path: /metrics
prometheus.io/port: "9099"
prometheus.io/scrape: "true"
Dapr provides three Prometheus Dashboards to monitor your Dapr applications and the Dapr control plane.
Finally, for logging to work, we will configure FluentD, ElasticSearch and Kibana and then add one more annotation to our function: dapr.io/log-as-json: "true"
The annotations in the final func.yaml file would look like this:
…
deploy:
…
annotations:
dapr.io/app-id: avg
dapr.io/app-port: "8080"
dapr.io/enabled: "true"
dapr.io/enable-metrics: "true"
dapr.io/metrics-port: "9099"
dapr.io/config: tracing
dapr.io/log-as-json: "true"
prometheus.io/path: /metrics
prometheus.io/port: "9099"
prometheus.io/scrape: "true"
So this looks great, but what are the current limitations and room for improvement?
I’ve identified a set of things that would make the experience of writing and running Dapr-enabled functions awesome:
- Serverless Sidecar on Knative Functions: because functions will be downscaled and upscaled based on demands, the Dapr sidecar will do too. Some Dapr functionalities require the sidecar to be up and running to receive external events, for example, Pub/Sub and Bindings. This basically means that while downscaling the sidecar to zero when nobody is using the function is a good thing, for some Dapr components, this pattern will not work. Also, because the sidecar will be upscaled with the function, we will end up with one sidecar per function replica. This is also not optimal. The fact that the sidecar can be downscaled to zero is also not working with tools like Prometheus scraping mechanisms, as if the function is downscaled, there is no endpoint to scrape the metrics. To solve this, we should investigate the use of the Prometheus Push Gateway for functions to push their metrics instead of requiring Prometheus to pull the metrics. Luckily, the Dapr community is already solving some of these issues.
- Ambient sidecars: there are sometimes when having sidecars is not possible or not efficient. For this kind of use cases having Deamonset (one sidecar per Kubernetes node) sidecars might make a lot of sense. You can find a proposal for shared sidecars here and how the OpenFunctions project is already solving these scenarios.
- Function templates with Dapr dependencies for quickstart: helping developers to get started with new tools is always a good idea. Leveraging the Knative Functions templates repository feature for the polyglot quickstart, which includes the Dapr libraries and Dapr client bootstrap code, is just one step closer to allowing your developers to focus on writing code and worry less about platform concerns such as infrastructure, observability, and security.
So, you might be wondering what's next? Definitely, Pub/Sub, Bindings, and Workflows are the building blocks that I will be investigating next. I am also interested in digging deeper into the Kubernetes Operator to understand how the Dapr Control Plane works. This means I will look at different patterns for doing GitOps (probably with ArgoCD) with Dapr and how that impacts the configurations required for the environments.
I am starting to think about building something like KonK (Knative On KinD) but including Dapr and Knative Functions to see how fast developers can get started with a combination of tools that are designed to speed up the delivery process at the same time are well-integrated for specific use cases such as Functions.
For now, that's all! Merry Xmas and I hope to see you all back in 2023!