
Building Cloud Native Platforms with Jenkins X
Today, Kubernetes plays an important role in the next generation of tools/platforms/services that will be created over the next few years. These new tools are going to shape the way that we create software that actually drives and evolve with our businesses. This blog post is about how using tools such as Jenkins X can help you to succeed while trying to reduce waste to better deliver software that actually makes a difference in how our business operates.
In the past 4 years, I’ve seen a radical change in the mindset of some developers out there that truly understand how Kubernetes is a game-changer and how it requires us to conceive, architect and implement software in a new way. As always, with “new ways”, there is resistance and it will take time until developers are convinced and understand the changes, the new methodologies and more importantly how to be efficient in this new territory. This blog post shares some of the lessons learned while moving from a monolith to a cloud native platform, what changed and how we managed to build really complex software for the cloud.
Before starting, it is important to make some points clear:
- Jenkins X is not Jenkins, I know it is confusing, but keep an open mind
- This blog post is not about how great Jenkins X is, it is more about the concepts behind it and what are the main changes that it proposes on how to developer Cloud Native applications (recommended link: https://jenkins-x.io/about/concepts/)
- I will not go into details of certain topics, such as a detailed description about how to install Jenkins X, or how it works step by step, etc, please feel free to drop me a comment with questions or suggestions for me to expand on certain areas.
This blog post is divided into three sections:
- Jenkins X high-level overview
- The Journey of Building Cloud-Native Applications
- Building your own “product/platform” on top of K8s
Let’s get started ...
Jenkins X high-level overview
If you are a developer, you like to write software, and if you are like me, you usually don’t care too much about how the software is delivered, you just want to write code. Someone will be responsible for testing it, packaging it and running it in production. As a developer you expect:
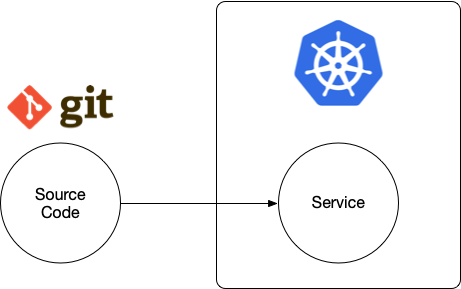
Now when you target Kubernetes, there are a lot of extra things to do besides writing the software itself. Now we need to care about containers, container registries, manifests, Helm Charts and how all these things are going to reach our favorite (s) cloud provider(s).
From a high-level perspective, Jenkins X helps us to make this a reality. But you can argue, there are some other tools that can solve these problems as well. You can spend a lot of time trying to configure a pipeline to deal with all the low-level details to take your source code, build it and then deploy it to an environment. You will spend most of the time trying to define how to do things, instead of actually doing stuff. All these definitions will need to be maintained over the time along with your software, and believe it or not if these pipelines add just a little overhead when creating a new project people will try to bypass them.
From the project perspective, Jenkins X goes several steps forward and it provides us with CI/CD/CD (Continuous Integration / Deployment / Delivery) on top of Kubernetes. It does it by relying on some key aspects:
- Built-in the Open, following Open Source practices: everything is done, discussed and implemented in the open. The maturity of the tools is directly related to people using it and reporting and fixing issues. Now as part of the Continuous Delivery Foundation, Jenkins X is helping to redefine CD for the cloud.
- Built and based on Kubernetes best practices, integrates natively with Kubernetes and follow Cloud Native practices: Jenkins X was designed from the ground up to work on Kubernetes, it integrates natively with the platform concepts and design patterns
- Continuous Delivery of the entire Jenkins X platform, a continuous stream of new versions: it allows you to get the latest fixes as soon as they are merged to the Jenkins X repositories.
- Multi-Cloud / Multi Environment support: When choosing Kubernetes, we open the door to run our applications/services into different cloud providers. Jenkins X was designed to leverage this multi-cloud support by using GitOps and enabling you to have different environments (QA, Testing, Production) in different clusters that can be hosted in different cloud providers.
All of the above means, fewer choices to make, which leads to more work done. You will go from having the source code and configurations of your services in Git to your services running in a Kubernetes Cluster. Just that is a lot to take in at the beginning. But in order to understand how all these happen, you also need to understand that change in mindset and the methodology that comes with this tool.
With Jenkins X, the picture looks more like this:
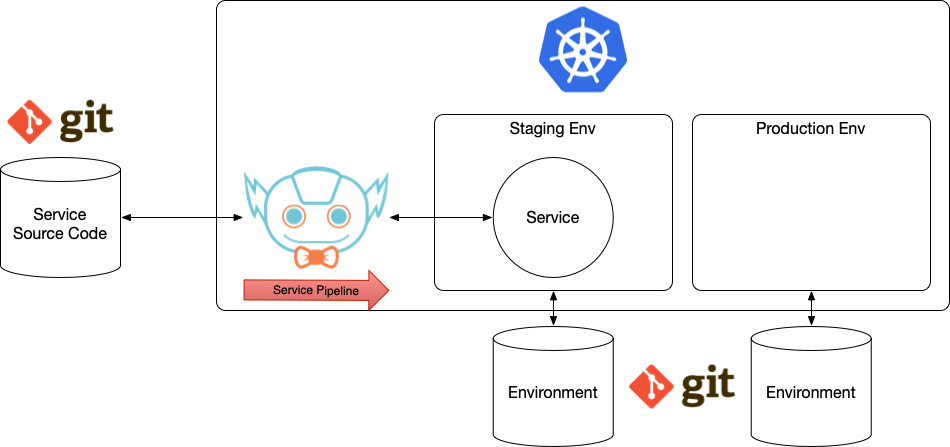
Jenkins X is now taking care of taking your source code and doing everything that is needed to have a service running inside an Environment. As you can see in the previous figure, Environments configurations are now stored in Git repositories and kept in sync with the cluster state.
These are the 5 key points that you should be aware while using Jenkins X:
- The most important change is that everything happens remotely. We have been building source code remotely for years now, but deploying and promoting these services in an automated fashion in a complex platform, such as Kubernetes, involve a lot of steps. Understanding why and how all these steps are required takes time.
- The second big change is that every change generates a release, that means your source code will be released as soon as a new change hit the master branch. If all the tests in your source code are green, your software will be packaged and released. Now, tests become more and more important, to guarantee that you are not releasing stuff that will not work. Once again, this for developers is just a massive change, and you need to work with it, in order to get your head around how all this will work in practice.
- The third thing is, now we are releasing more artifacts than before. Coming from the Java background, we are used to releasing Jars to Maven Central/Nexus/Artifactory, but now we need to care about Docker Images and Helm charts and they all need to be synchronized. Automating all these building, releasing and deploying to different repositories makes a lot of sense, but no matter how the automation happens, we need to understand what is going on under the covers.
- The fourth thing is GitOps, managing environments and infrastructure as code is a massive win. With this approach, the configuration and the state of our environments are stored in a Git repository which is kept in sync with these environments. Before the cloud era, this was an Ops topic, nowadays developers are encouraged to learn and practice GitOps into their day to day workflow. This is due, tools like Jenkins X which makes it extremely simple and transparent. In the way that it is implemented in Jenkins X you definitely need to understand how Helm works, once again something quite close to the Kubernetes community.
- Finally, you can rely on cost-effective pipelines that are only active when something needs to be built relying on Tekton and Knative Serving. The benefits that we get from this is massive, but again from a Developer perspective, if you want to understand how things are working in Jenkins X, now you need to learn about not only K8s but also Knative and Tekton.
The best way to get your head around Jenkins X is to try it with one of your projects. First of all, you gain an understanding of what it really takes to deploy your services into Kubernetes and see the advantage of having all these automated. You also learn a methodology on how to do all these steps in a repeatable fashion, following best practices that are coming from the Kubernetes and Jenkins Communities. This is a huge win, you will not be inventing your own practices, you will be standing on the giants' shoulders.
As a developer this is how the flow looks like after installing Jenkins X:
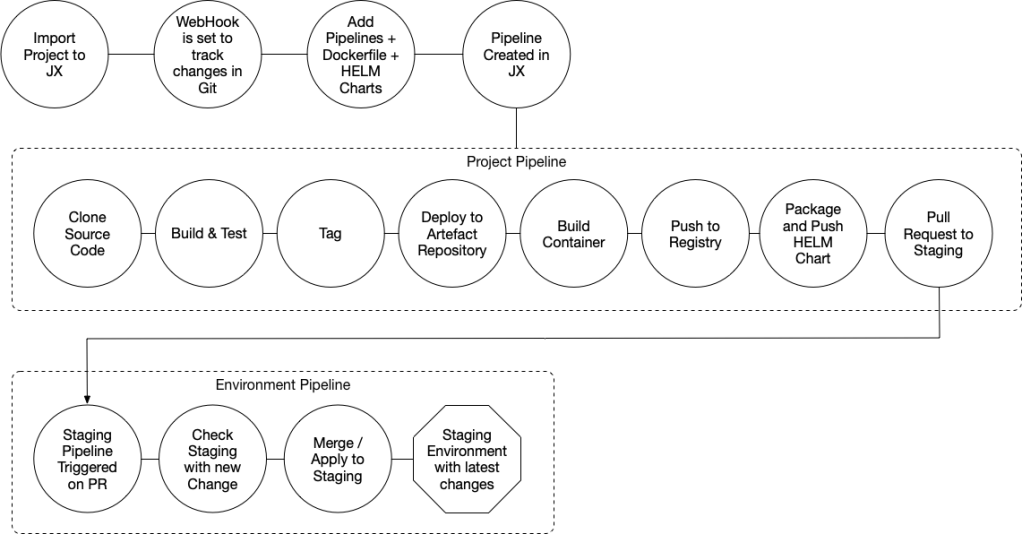
As you can see, there are 3 phases:
- Importing your project into the platform (Jenkins X): here we are just creating all the configurations for our project to be built correctly. Jenkins X achieve this by decorating our project source code with some configuration files (most of them rely on conventions) such as the pipeline configuration, Dockerfile, Kubernetes Manifests, and Helm Chart definitions.
- Project Pipeline: this pipeline will be executed for every change that hits the master branch of our repository. The steps involve everything needed to build, package and release our project binaries, docker image, and helm charts. If everything is ok, the last step creates a PR to the staging environment which represent the promotion of the new version of our service to the staging environment.
- Environment Pipeline: this pipeline is executed for every Pull Request created to our staging and production environments. This pipeline is in charge of validating the PRs and merging them, which causes the running environments to be updated with the new version of our services.
As soon as you get used to working in this way, you can get your services to Kubernetes very fast. But what happens when you have 80+ projects? What happens when you have dependencies between your projects? Let’s try to shed some light based on my experience of moving from a monolith big web application to a Cloud-Native architecture by using Jenkins X and learning from the Jenkins X team practices.
The Journey of Building Cloud-Native Applications
In my previous life (large Open Source project), we started with a big monolith web application and we decided to explore a cloud-native approach to solve some major problems in the monolith. We quickly realized that CI/CD helped us to iterate fast and compensate for our mistakes. For the sake of simplicity, we will be looking at a Conference “Platform” to exemplify some of the main challenges and lessons learned:
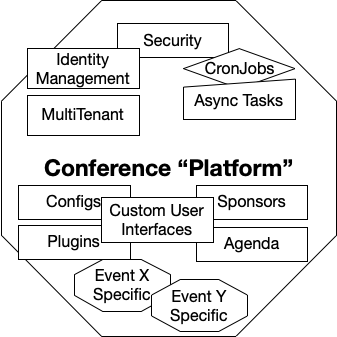
The monolith application was really complex, allowing users to create and host their own conference sites. The platform itself contained a lot of code to deal with cross-cutting concerns, such as Identity Management, security, configurations, multitenancy and common frameworks for dealing with User Interfaces. It also has some core services related specifically to conferences such as Sponsors and Agenda functions that allow people to customize the behavior of these sections in the site. Finally, it provided a Plugin mechanism where users can plug in their own custom behaviors into the platform itself. It was also considered as an extension point the fact that code could be added to the platform if the extensions mechanisms were not enough to cover some use cases, polluting the platform itself.
With this approach, we had a mono repo, in other words, a single git repository containing all the source code of the platform. This slowed down the teams working in different areas of the monolith since releasing was done with a single pipeline and there was only a single release train. This platform caused a lot of problems related to modularity and reusing code that was created for previous conferences, the fact that it was a monolith you can choose to use all or nothing. The platform itself became really complex and all the custom code that was added for very specific cases stayed forever. Another big concern, and one of the main reasons to explore a cloud-native approach was the fact that conferences couldn’t be scaled independently. With this platform, you needed to scale the entire platform if you wanted to scale a single “very popular” conference.
In order to start our cloud native journey, we wanted to experiment and clearly understand the shape of each of these conferences by following cloud-native patterns.
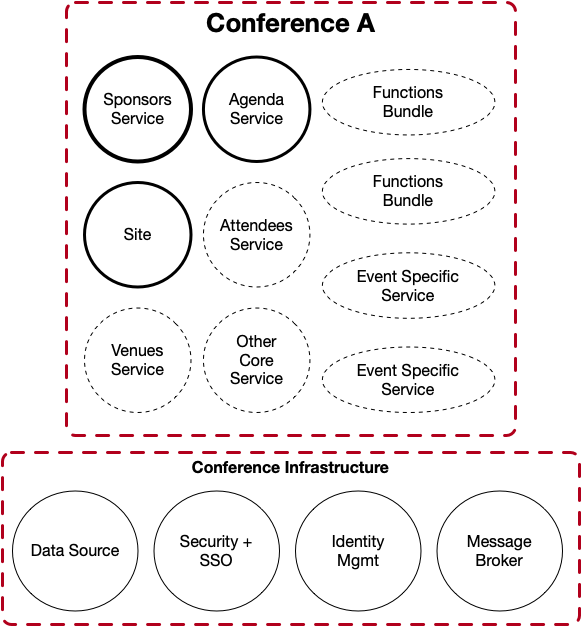
A cloud-native conference (notice that this is not a platform, it is just a single conference instance) would use a set of services to provide all the functionality needed for that event. The conference itself will be composed by core services (that can be reused for other events), custom services required by that specific event and shared or custom functions that can be easily created from a web interface (in contrast with custom services which need to be coded). Notice that the conference cannot run on its own, it requires a set of services which are considered to be part of the conference infrastructure, such as databases, message brokers, identity management, etc. These infrastructural services are usually provisioned by the cloud provider where you are running your application, for that reason, our services should understand how to connect and interact with these services.
Now, how do you get one of these “complex” conference applications from source code to running?
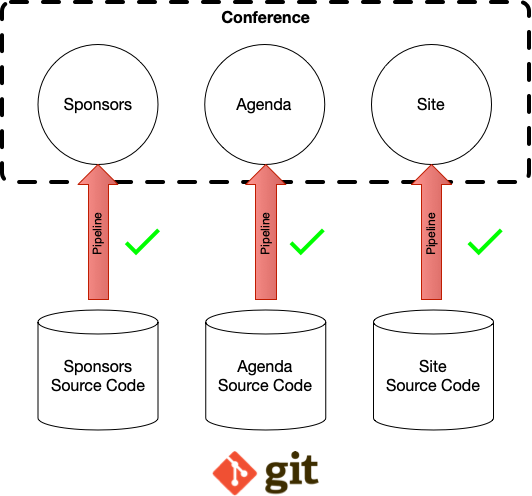
Now with this approach, each service inside our conference will have its own git repository and pipeline. Allowing us to evolve each of them individually, by different teams. For each service inside a conference, we have a pipeline that is in charge of building, releasing and deploying our services. These pipelines will monitor the source code in each repository and trigger a release for each change that land on the master branch. For each service, there is a pipeline definition and Jenkins X will run that pipeline, but there is no concept of Conference here. Pipelines are not aware of how conferences are composed so they run independently for each of our services.
The “Conference” concept is something very domain-specific and while analyzing the pipelines and services relationships we can clearly notice that we will need to deal with this higher-level concept sooner than later.
Before moving forward, let’s get another slap in the face from reality. In the Java world, each service depends on a set of Java libraries that also need to be released. And this is quite normal, you will never be able to build a real-life service with zero dependencies. Part of those dependencies which brings business value, like domain-specific algorithms, will require a separate release lifecycle to handle the changes in the libraries. So, in reality, we had something like this:
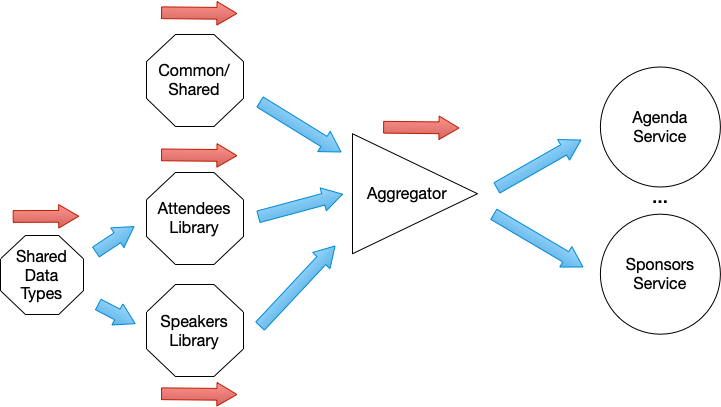
On the left side (octagons) are Java Libraries and the arrows represent their dependencies. In order to build “Attendees Library” for example, you need “Shared Data Types”, and if something changes in “Shared Data Types”, “Attendees Library” will need to be updated to consume the latest version. The Aggregator (triangle) helped us to bundle a set of libraries with their respective versions under a single version, meaning that each library can evolve independently and the aggregator now will have the responsibility to check that the set of libraries are consistent and working as expected.
Each of these libraries requires a pipeline to be released and we used and abused the Jenkins Update Bot project to notify all these pipelines activities and dependencies. Update Bot helped us to automate all these pipelines triggering by notifying (via Pull Requests) other repositories about one (or more) of their dependencies were updated.
This pushes you to start thinking of “gates” (black bars in the following diagram) to control how and when your pipelines will be executed based on the project dependencies. These gates stop changes of being propagated until the consistency is checked on a set of dependencies. These gates are domain-specific restrictions and verifications that need to be done in order to reduce possible issues with version mismatches.
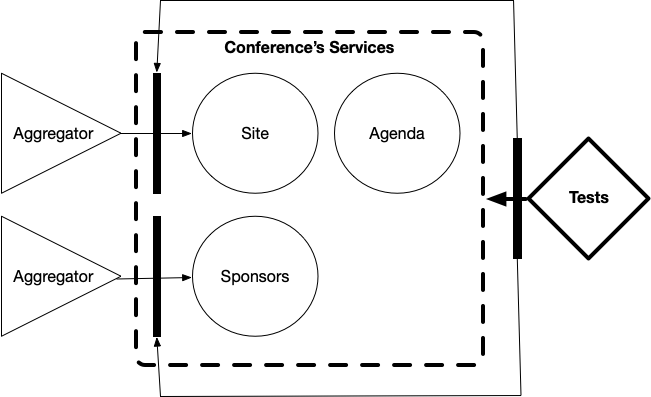
Another layer of validation and testing needs to be added to check the whole set of running services (per conference). As you can see in the following diagram, we used Helm Charts to describe how a conference is composed and we used “Acceptance Tests” to gate the release of these charts.
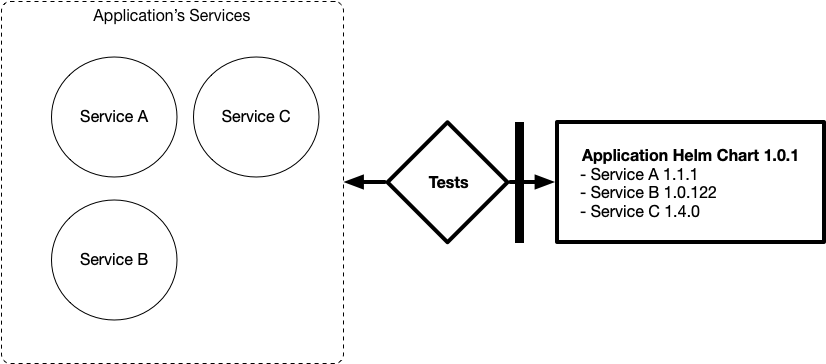
Now if you want to install a specific version of this application in a different cluster, you just install the Application Helm Chart with a single command. This Helm Chart receives updates from each of the services when a new release is created. This allows us to run tests every time that a version is updated and also decide when it is the right time to publish a new version of the chart.
Now you have a way to describe and package complex applications that you can move around to different cloud providers. At this point in time, we were able to provide a continuous stream of releases for our conferences. How cool is that? It wasn’t simple, Jenkins X solved most of these problems for us, but it takes team maturity to understand how to apply all these concepts together.
Here are the key lessons that we got from our experience:
- Give back: at every step, we reported and tried to fix issues that we found while using Jenkins X. By doing this we learned a lot about the project direction and how to avoid some common pitfalls.
- Share with other developers: we presented in several meetups to gather feedback about how other people were solving the problems that we were facing (using other tools)
- Understand when to build and when to integrate: Having a clear set of guidelines on what is really adding value to our business and what can be integrated from a third party was an exercise that made our team strong and allowed us to accelerate
You might be thinking that this is extremely complex. But it becomes even more complex if you’re providing pipelines as a service for your customers. Scenarios where your Customers want to plugin their own conferences and/or extensions require more advanced solutions.
This also opens the door to think about, how can our domain-specific products, services, platforms leverage the power of Jenkins X? Can we provide a continuous stream of versions for our products? Can we leverage the Open Source communities and follow the same practices to go as fast as the Jenkins X team is going (4000+ releases a year)?
Building your own “product/platform” on top of K8s
Having our applications defined as Helm Charts was a good approach, but in real life, this is not enough. We needed to move one step forward into integrating with Kubernetes if we wanted to make our conferences feel like first-class citizens inside the platform. We could not expect our users to provide us a Helm Chart and deal with hosting all the docker images for their applications. We knew that we will need higher-level abstractions and tools to make our users’ lives easier.
At this point, we started researching how to integrate with Kubernetes in a more native way, and once again, Jenkins X served us as the perfect example. In Kubernetes, a way to extend the platform and allow it to understand about your custom concepts (Applications, Conferences, Domain-Specific Services, Extensions) is to use Custom Resource Definitions (CRDs).
As soon as you create a Custom Resource Definition you open the door for native integrations inside the Kubernetes Ecosystem.
Based on the previous example, the Conference concept is a perfect candidate for making Kubernetes understand about how to deal with our complex conference applications. We can create a Conference Resource Definition to look like:

The Conference CRD (Resource Definition) defines the Conference topology and metadata, in other words, which services do belong to a particular conference instance.
If we create a new conference resource now, we can describe which services are required to provide all the functionality that is needed for a conference. In other words, the resource serves as conceptual glue to monitor and manage an entire set of services that are related.
From an operational point of view, now you can deal with conferences instead of isolated services. Now you are enabled to deal with topics such as Security Policies, Traffic Routing, Scalability, etc at the conference level, meaning that you can tailor each of these concerns specifically to conferences and their needs, instead of defining them generally for each service.
But the Conference Resource Definition doesn’t do anything on its own, you need a component to manage these new resources lifecycle. In Kubernetes, these components are usually referred to as Controllers or Operators.
A Kubernetes Operator wraps the logic for deploying and operating a complex application using Kubernetes constructs. For our conferences, we needed to have a component that understood the Conferences Lifecycle and had fine-grain control for traffic rules to deal with things such as versioning, A/B tests, security, etc.
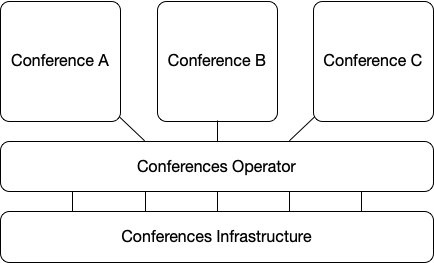
In this case, our Conference Kubernetes Operator had to understand the nature of our conferences, how they are composed and their state. Based on this understanding it could monitor, repair and notify us about issues with our conferences.
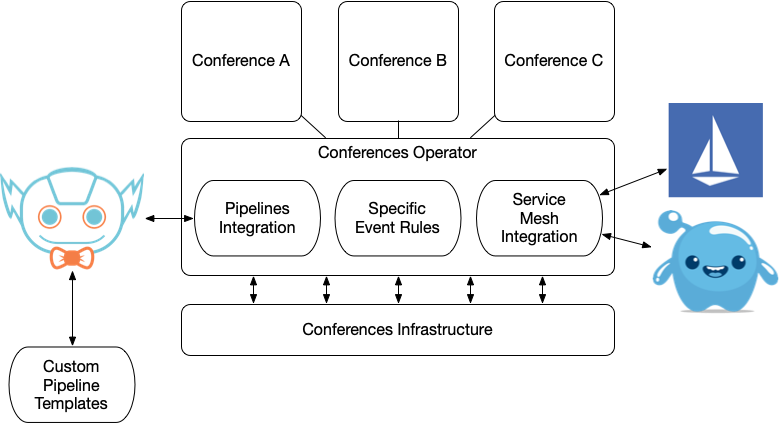
An important point here is: the Operator is not responsible for promoting / deploying applications. Our pipelines are. But the Operator can definitely be aware and control pipelines and promotions to different environments.
A more complex view of out Operator would integrate with Tekton Pipelines and if you are using a service mesh like Gloo or Istio, your operator can be in charge of routing traffic to a specific application and configure more restricted security policies when needed:
If you are thinking about third (external) parties extending or adding services to your platform, you want to hide all the internal complexity and offer new pipelines customized for these applications/extensions. You can reuse all the goodness of Jenkins X to have a pipeline looking more like:
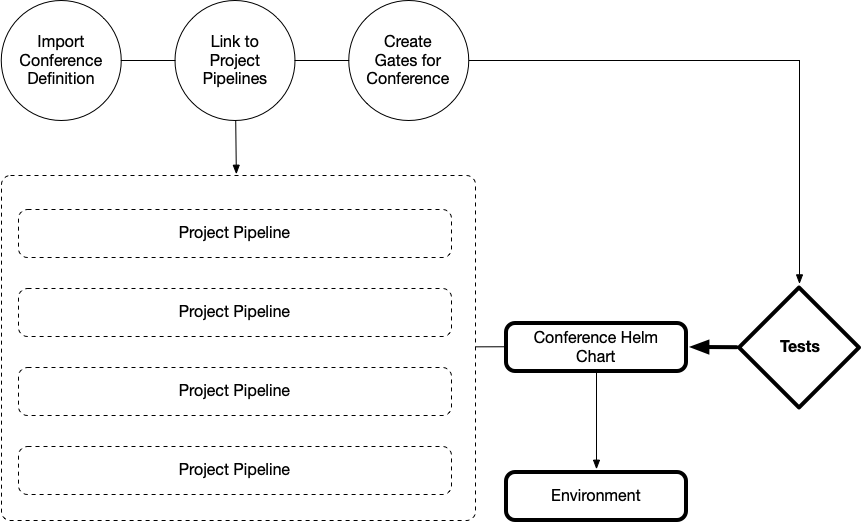
This enables users/customers/operators to think about what they really care “Conferences” and not the low-level services that are providing internal functionality.
You might be thinking, this is all really nice, but how can I get started with all the topics that were covered in this blog post?
As usual, a good place to start is to give Jenkins X a try. You need the JX CLI (https://jenkins-x.io/getting-started/install/) and then you can use GKE free trial to create a Kubernetes cluster by following this tutorial https://jenkins-x.io/getting-started/create-cluster/#using-google-cloud-gke
I’ve also created a demo of the Conference Use Case which is covering:
- Single Conference Monolith approach
- Split into Multiple Service, Multiple Pipelines, from source code to a service running in Kubernetes Staging Environment
- A Conference might require multiple services
- Helm Chart aggregation using Update Bot and Pipelines Dependencies
- Conference Custom Resource Definition (CRD)
- Kubernetes Conference Operator:
- Integrates with Jenkins X & Tekton Pipelines to infer the state of the conference
- Creates/Deletes Ingress definitions to expose only conferences that are Healthy
- Exposes a Conference Dashboard for Operations and Monitoring
The following video shows some of these concepts in action and points to the Github repositories that contain the example configurations:
https://www.youtube.com/watch?v=TsonCK6YAAM Conferences Demo
Links to source code:
- Conference Monolith:
- Conference Cloud Native:
- Conference Helm Chart Aggregator
- Conference Operator
- Jenkins X - Staging Environment
Conclusions
Nowadays, with a vibrant Kubernetes community, as developers, we are allowed to concentrate on what is important to our business, instead of building components that can be easily provisioned by the underlying infrastructure (cloud provider). This is easier said than done. It takes a lot of expertise and intimate knowledge of where Kubernetes community is headed next to make the right choices, but more importantly, it requires the team to be flexible enough to pivot and fix mistakes as soon as they appear. Even if your team is flexible enough, the entire organization needs to be ready to change its practices and how software is monetized and delivered.
Jenkins X provides us with a great Open Source example on how a Cloud-Native Product can be built in a very efficient way and also give us a methodology to follow. The more you use Jenkins X the more you forget about CI/CD and focus on what is important for your work.
Moving forward, I can see a new breed of applications that take advantage of the platform where they are running in very domain-specific ways. This leads me to think that new tools and patterns will start to surface from the experience of building these custom components. This will enable more business-related aspects to be automated and streamlined as we are now doing with CI/CD. Hopefully, business automation technologies go towards this direction, where you basically forget that these tools are there, but are so embedded in your day to day practices that they feel natural to work with.
If you have questions, comments or if you want to clarify some points mentioned in this blog post, get in touch. I am happy to extend the example to cover more complex use cases if someone else jump in to help.