
LDD 3: #5 Concurrencia y condiciones de corrida (de mi blog en www.jugmza.com.ar)
Concurrencia es cuando el sistema trata de hacer mas de una cosa a la vez. Y el manejo de esta concurrencia es uno de los core problems en la programacion de Sistemas Operativos. Los bugs relacionados con la concurrencia son los mas faciles de crear y los mas dificiles de encontrar.
En los primeros kernel habian relativamente pocas fuentes de concurrencia (ya que SMP no era soportado) y la unica causa de ejecuciones concurrentes era el uso de interrupciones de hardware. Pero en respuesta al nuevo hardware y las nuevas aplicaciones el kernel evoluciono y muchas cosas pasan simultaneamente.
Condiciones de corrida, por otro lado, son el resultado de accesos no controlados a datos compartidos. Estos accesos no controlados producen resultados inesperados (ya que por ejemplo un proceso puede pisar los datos de otro)
CONCURRENCIA Y SU MANEJO:
En los sistemas linux actuales, hay un gran numero de fuentes de concurrencia y por esto posibles condiciones de corrida.
Hay que tener en cuenta de que el codigo de kernel es preemptible (es decir, que el codigo del driver puede perder el procesador en cualquier momento y el proceso que lo reemplaza puede estar corriendo en nuestro driver tambien)
Tambien las interrupciones (eventos asincronos) pueden causar ejecuciones concurrentes de nuestro codigo.
En el mundo hotplugueable de hoy en dia, nuestro dispositivo puede desaparecer mientras estamos trabajando con el.
Entonces como hace el programador de drivers para evitar la creacion de caos absoluto?
• Usa primitivas de kernel para el control de concurrencia • Tiene en cuenta algunos principios basico anti concurrencia
Las condiciones de corrida, como habiamos dicho antes, vienen como resultado del acceso compartido de los recursos. Cuando dos hilos de ejecucion tienen que trabajar con la misma estructura de datos (o recurso de hardware) la posibilidad de mezcla existe. Entonces primera regla para el disenio de nuestro driver: "Evitar los recursos compratidos cuando sea posible". La aplicacion mas obvia de esta regla es evitar el uso de variables globales.
El problema es que este compartimiento es por lo general requerido. Los recursos de hardware, por naturaleza, son compoartiudos y los recursos de software or lo general tiene que estar disponibles para mas de un hilo de ejecucion.
Hay que tener en mente que las variables globales no son la unica manera de compartir datos, cada vez que nuestro codigo pasa un puntero a otra parte del kernel, estamos potencialmente creando una situacion de comportacion. "Compartir es un hecho de la vida".
REGLA DURA DEL COMPARTIMIENTO DE RECURSOS:"Cada vez que un recurso (hard o soft) es compartido a travez de un hilo de ejecucion, y existe la posibilidad de que un hilo pueda encontrar un estado inconsistente del recurso, debemos explicitamente administrar el acceso al recurso".
La tecnica mas comun para la administracion de acceso es llamada LOCKING o EXCLUSION MUTUA.
Antes de ver estos temas otra regla importante: "CUando codigo de kernel crea un objeto que va a ser compartido en cualquier otra parte del kernel, este objeto debe continuar existiendo (y funcionando correctamente) hasta que no haya mas referencias exgternas a el".
Esta regla trae consigo 2 requerimientos: • Ningun objeto puede hacerse disponible hasta que este en un estado de correcto funcionamiento. • Todas las referencias a estos objetos deben ser trackeadas(ref count) (en la mayoria de los casos el kernel se encarga de las referencias pero hay excepciones)
SEMAFOROS Y MUTEXES:
La meta de agregar locking a nuestra aplicacion es que las operaciones sobre nuestras estructuras de datos sean atomicas. Para esto tenemos que definir y marcar las secciones criticas (que son las secciones de codigo que pueden ser ejecutadas por solo un thread a la vez). Pero no todas estas secciones criticas son iguales. Por esto el kernel provee diferentes primitivas para diferentes necesidades. En esta contexto usamos mucho la frase "go to sleep". en los casos donde un proceso llega a un punto dende no puede seguir su flijo de proceso, "se va a dormir" (o se bloquea) cediendo el procesador a alguien mas hasta que en algun punto en el futuro el pueda seguir haciendo su trabajo y se despierte. Por lo general los procesos duermen cuando se quedan esperando que operaciones de I/O se completen. A medida que vamos entrando en las profundidades del kernel veremos bastantes situaciones donde no podemos dormir.
Los semaforos son un concepto bien entendido en las ciencias de la computacion. Como nucleo tenemos que un semaforo es un solo entero combinado con un par de funciones que son tipicamente llamadas P (down) y V (up).
Cuando un semaforo es usado para exclusion mutua - mantener multiples procesos corriendo con una seccion critica simultaneamente - el valor inicial se setea en 1. Este semaforo puede ser posieido por un solo proceso o hilo en un tiempo determinado (esto es llamado MUTEX).
IMPLEMENTACION DE SEMAFOROS EN LINUX (<asm/semaphore.h>)
El tipo mas utilizado es struct semaphore e inicializamos esta struct con:
void sema_init(strcut semaphore *sem, int val);
Donde val es el valor inicial del semaforo.
Para hacer esto mas facil el kernel provee un set de funciones y macros. Por ejemplo para la inicializacion:
declare_mutex(name) -> setea al semaforo de nombre name en 1 declare_mutex_locked(name) ->setea al semaforo de nombre name en 0
Si los mutex van a ser inicializados en runtime:
void init_mutex(struct semaphore *sem) void init_mutex_locked(struct semaphore *sem)
Luego tenemos la funcion down que decremente el valor del semaforo, esta funcion viene en 3 versiones:
void down(struct semaphore *sem) void down_interruptible(struct semaphore *sem) voide down_trylock(struct semaphore *sem)
down decremente el valor del semaforo y espera tanto como deba esperar. down_interruptible hace lo mismo pero la operacion es interumpible (esta es la que mas vamos a usar). Permite al usuario (proceso en el user-space) interrumpir el proceso. "No debemos usar operaciones no interumpibles a menos que no tengamos alternativa". (las operaciones no interrumpibles son buenas para crear procesos inmatables (dreaded "D state" cuando tiramos un ps)). Pero ojo que usar down_interruptible requiere un cuidado extra. Ya que si la operacion es interrumpida,se devuelve un valor que no es cero y el que llamo a la funcion deja de poseer el semaforo. POr lo tanto un uso adecuado de down_interruptible requiere siempre que revisemos el valor de retorno y actuemos acordemente en base a el.
La version final de down_trylock nunca duerme, si el semaforo no esta disponible a la hora de llamarlo, down_trylock devuelve inmediantamente un valor no cero.
Una vez que un hilo ha exitosamente llamado a algun version de down. se dice que ese proceso tiene el semaforo. Este hilo ahora tiene el poder de acceder a la seccion critica protegida por el semaforo. Cuando las operaciones que requieren exclusion se completaron el semaforo tiene que ser devuelto con:
void up(struct semaphore *sem)
La clave de usar bien semaforos esta en especificar bien que vamos a proteger.

SEMAFOROS DE LECTURA/ESCRITURA:
Los semaforos proveen exclusion mutua para todos los llamantes, sin importar que es lo que el hilo quiera hacer. La mayoria de las tareas se pueden dividir en 2 tipos: • Lectura de los datos protegidos • Cambios (o escritura) de los datos protegidos
Por lo tanto es posible tener muchos lectores concurrentes, mientras nadie trate de hacer ningun cambio. Hacinedo esto optimizamos la performance, ya que las tareas de solo lectura pueden hacer su trabajo en paralelo sin tener que esperar a que otros lectores salgan de la seccion critica. Para esto linux provee un tipo espacial de semaforo llamado rwsem (<linux/rwsem.h>) Y tenemos las funciones para actuar sobre el:
Inicializacion void init_rwsem(struct rw_semaphore *sem) Lectura void down_read(struct rw_semaphore *sem) int down_read_trylock(struct rw_semaphore *sem) void up_read(struct rw_semaphore *sem) y las funciones para escritura void down_write(struct rw_semaphore *sem) int down_write_trylock(struct rw_semaphore *sem) void up_write(struct rw_semaphore *sem) void downgrade_write(struct rw_semaphore *sem)
Entonces rwsem permite que un escritor o una cantidad ilimitada lectores tenga el semaforo. Los escritores tienen prioridad. Cuando un escritor entra a la seccion critica ningun lector podra acceder. Por esto rwsem es usado cuando el acceso para escritura son por periodos cortos y ocurren casi nunca y tenemos muchos accesos de lectura. COMPLETIONS:
Un patron comun en la programacion del kernel involucra inicial alguna actividad fuera del hilo actual y luego esperar a que esta actividad se complete. Esta actividad puede ser tanto la creacion de un nuevo hilo de kernel o un proceso de espacio de usuario, un request a algun proceso existent, o alguna accion sobre algun hardware. EN esto casos puede ser tentador usar un semaforo para sincronizar las dos tareas:
EJ:
struct semaphore sem; init_mutex_locked(&sem); start_external_task(&sem); down(&sem);
Luego en external task se llama a up(&sem) cuando se termina esa tarea. Como se puede ver los semaforos no son la mejor herramienta para usae en esta situacion. ya que en un uso normal el codigo que trata de obtener un semaforo lo encuentra siempre disponible. Si hay una disputa por este semaforo la performas va a sufrir y el esquema de lockeo tendra que ser replanteado. POr eso los semaforos han sido fuertemente optimizados para estos casos de disponiblidad. Cuando usamos para comunica finalizacion de tareas como mostramos antes, el hilo que llama a down siempre tiene que esperar y con esto la performance tambien sufre.
Para solucionar estos problemas surge COMPLETIONS que son un mecanismo liviano que cumple con una sola tarea: "permitir a un hilo decirle a otro que el trabajo esta hecho". Para usar esta funcionalidad (<linux/completion.h>):
declare_completion(my_completion) o si queremos crearla e inicializarla dinamicamente: struct completion my_completion; init_completion(&my_completion);
Y esperar por la completitud de una tarea es facil: void wait_for_completion(struct completion *c);
Hay que notar que esta funcion realiza una espera ininterrumplible. Si nuestro codigo llama a esta funcion y nunca nadie termina la tarea, el resultado es un proceso inmatable. POr el otro lado la completacion de una tarea se seniala llamando:
void complete(struct completion *c) void complete_all(struct completion *c)
Estas dos funciones se comportan distinto si mas de un hilo esta esperando por el mismo evento de completacion. "complete" despierta a solo uno de los hilos que esta esperando.
SPINLOCKS:
Los semaforos son una herramienta util para exclusiones mutuas, pero no son las unicas herramientas provistas por el kernel. Por esto la mayoria del locking implementado en el kernel esta implementado con un mecanismo llamado spinlock. A diferencia de los semaforos son usado en codigo donde NO SE PUEDE DORMIR, como por ejemplo manejadores de interrupciones. Cuando son correctamente usados, los spinlocks ofrecen mejor performance que los semaforos. Pero ellos traen todo un set de restricciones para su uso.
Spinlock es un concepto simple: es un dispositivo para exclusion mutua que puede tener solo 2 valores (locked y unlocked). usualmente esta implementado como un solo bit en un valor entero. EL codigo interesado en tomar un lock en particular revisa este bit; si el lock esta disponible, se setea el bit de locked y el codigo continua en la seccion critica. En cambio si el lock ha sido tomado por algien mas el codigo entra en un loop donde repetitivamente revisa el bit de lock hasta que este disponible. Este loop es la parte spin de spinlock. La operacion de "test y set" debe ser atomica asi un solo hilo puede obtener el lock, a pesar de que varios esten loopeando al mismo tiempo.
INTRODUCCION A LA API DE SPINLOCK (<linux/spinlock.h>)
El tipo importante aca es: spinlock_t y para inicializarlo usamos: spinlock_t my_lock=spin_lock_unlocked; o en runtime void spin_lock_init(spinlock_t *lock);
Y luego antes de entrar en una seccion critica hacemos: void spin_lock(spinlock_t *lock)
Esta llamada tambien genera esperas ininterrumpibles. Una vez que llamamos spin_lock se va a loopear hasta que el lock este disponible.
Para liberar el lock hacemos: void spin_unlock(spinlock_t *lock)
SPINLOCKS Y CONTEXTOS ATOMICOS:
• REGLA DE ORO: " cualquier codigo que tiene un spinlock debe ser atomico. no puede dormir, no puede ceder el procesador por ninguna razon, excepto por las interrupciones (a veces ni siquiera)" • Cada vez que el codigo del kernel obtiene un spinlock se desactiva el preemption en ese procesador. Hay que evitar dormir mientras tenemos un spinlock y esto puede ser dificil. Por lo tanto escribir codigo que se ejecuta cuando tenemos un spinlock requiere presetar atencion a cada funcion que llamamos.

FUNCIONES DE SPINLOCK:void spin_lock(spinlock_t *lock)
void spin_lock_irqsave(spinlock_t *lock, unsigned long flags) Esta funcion desabilita las interrupciones de hard y soft en el procesador local. Las flags representan al estado anterior de las interrupciones que se deshabilitan
void spin_lock_irq(spinlock_t *lock)
void spin_lock_bh(spinlock_t *lock) Esta funcion deshabilita solo las interrupciones de soft
Luego tenemos las mismas funciones de unlock
SPINLOCKS LECUTRA/ESCRITURA: exactamente igual que los semaforos. la misma idea..
LOCKING TRAPS:
El concepto y la utilizacion de locking es dificil de entender bien. La administracion de la concurrencia es bastante complicada y hay muchos errores que podemos cometer. Entonces vamos a ver que cosas pueden ir mal. REGLAS AMBIGUAS:
Un esquema de locking requiere reglas claras y explicitas. Cuando creamos un recurso que puede ser accedido concurrentemente, debemos definir que lock va a controlar el acceso a dicho recurso. Para que nuestro locking funcione bien, tenemos que escribir funciones que tengan el conocimiento de que el que las llamo ya tiene el/los lock(s) relevantes. (sino seguro que causamos un deadlock)
REGLAS DE ORDEN PARA EL LOCKEO
En sistemas con una gran cantidad de locks no es raro tener que obtener mas de un lock a la misma vez. Pero tomar multiples locks a la misma vez puede ser peligroso. POr ejemplo: si tenemos 2 locks: LOCK1 y LOCK2 y el codigo necesita obtener los dos al mismo tiempo podemos llegar a tener un deadlock. Imaginemos que un hilo toma el lock1 mientras que otro hilo toma el lock2. Luego ambos tratan de obtener el que no tiene y ahi se produce un deadlock. La solucion a este problema es por lo general simple: "cuando debemos obtener multiples locks, siempre debemos adquirirlos en el mismo orden".
ALTERNATIVAS A LOCKING:
ALGORITMOS LOCK-FREE
A veces podemos re pensar nuestros algoritmos para evitar el uso de locking. En casos donde hay multiples lectores y un solo escritor casi siempre se puede trabajar sin locking. Si el escritor tiene conciencia de que la estructura de datos siempre sea consistente para los lectores, podemos crear una estructura de datos libre de locks.
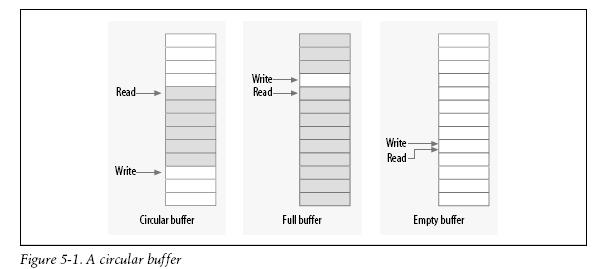
Una estructura de datos que puede ser usada para tareas de productor/consumidor sin locks son los buffers circulares. Este algoritmos involucra a un productor que pone datos en un extremos de un array, mientras que el consumidor saca del otro extremo. Cuando se llega al fin del array el productor vuelve al principio. Por esto un buffer circular requiere de un array y dos valores que indican donde va el nuevo valor y que valor debe ser removido a continuacion (uno para la lectura y otro para la escritura). El productor es el unico hilo que tiene permiso para modificar el valor del indice de escritura y la posicion donde apunta en el array. Mientras el productor escriba un nuevo valor en el buffer antes de cambiar el valor del indice. El/los lector(es) siempre veran un buffer consistente. Por otro lado el lector es el unico que puede modificar el indice de lectura y acceder al valor que apunta. Con un poco de cuidado de que ninguno de los 2 punteros sobre escriba al otro, el productor y el consumido pueden acceder al buffer concurrentemente sin condiciones de corrida
VARIABLES ATOMICAS:
A veces un recurso compartido es simplemente un entero. Y a este entero queremos incrementarlo con: nro++; donde esta operacion requeriria locking. Pero todo el esquema de locking parece mucho para manejar solo un entero. Para esto existen la variables de tipo entero atomicas: atomic_t -> (<asm/atomic.h>) Entonces tenemos las funciones: atomic_set(atomic_t *v,int i), atomic_read(..), atomic_add(), atomic_sub(), atomic_inc(), atomic_dec();
OPERACIONES DE BITS:Atomic_t es bueno para enteros pero poco performante cuando tenemos que manipular bits. Entonces tenemos las mismas funciones que para atomic pero para bit...
SEQLOCKS:
El kernel 2.6 contiene un par de nuevos mecanismos para intentar proveer acceso rapido y sin locks a recursos compartidos. SEQLOCKS funciona en situaciones donde el recurso a proteger es pequenio, simple y frecuentemente accedido, y donde el acceso de escritura es raro pero debe ser rapido. Escencialmente, funciona permitiendo a los lectores el libre acceso a los recursos pero requiriendo que los lectores revisen las posibles colisiones con los escritores, y cuando una colision ocurre, los lectores deben reintentar su acceso. Los SEQLOCKS generalmente no pueden ser usados para proteger estructuras con datos que contengan punteros, ya que los lectores podrian estar siguiendo punteros invalidos mientras el escritor esta cambiando la estructura de datos.