
LDD 3: #3 Char Drivers (de mi blog en www.jugmza.com.ar - 11/12/07)
Vemos char drivers porque son los dispositivos de hardware mas simples, El primer paso cuando escribimos un driver es definir las funcionalidades(mecanismo) que el driver le ofrese a sus usuarios.
MAJOR and MINOR numbers:Accedemos a los dispositivos de caracteres mediante nombres en el filesystem (device files o nodos del fs. EJ: /dev/*)
Los char drivers son identificados con una c (y los block drivers con una b) cuando hacemos un ls -l /dev/.
Tambien vemos dos numeros separados por como, estos son el MAJOR y el MINOR number de cada dispositivo.
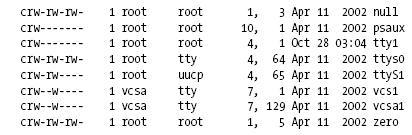
MAJOR -> identifica el driver asociado al dispositivo (EJ: /dev/null y /dev/zero -> driver 1)
MINOR -> es usado por el kernel para determinar exactamente que dispositivo se esta referenciando.
Dependiendo de como escribamos el driver podemos obtener un puntero del kernel al dispositivo o podemos usar MINOR para tener un indice local de un array de dispositivos.
REPERESENTACION interna de los device numebers:
En el kernel tenemos el tipo dev_t (definido en <linux/types.h) que es usado para almacenar los device numbers. Tenemos macro para setear estos numeros (MAJOR(dev_t dev) y MINOR(dev_t dev)) -> Obtenemos (le pedimos al kernel) un numero de dispositivo.
Si ya los tenemos y los queremos asignar: mkdev(int major, int minor)
RESERVANDO y liberando device numbers:una de las primeras cosas que nuestro driver a a tener que hacer a la hora de configurar cada char device es obtener uno o mas device numbers para trabajar. La funcion necesaria para hacer esto es:
int register_chrdev_region(dev_t first, unsigned int count, char *name)
Donde first es el primero de un rango de device numbers que queremos obtener. El MINOR de first por lo general es 0. Y count es el numero total de device numbers contiguos que queremos obtener. Finalmente name es el nombre asociado a este rango de numeros que aparecer en /proc/devices y sysfs
register_chrdev_region funciona bien si sabemos de antemano que device numbers queremos. Generalmente no sabemos que major number usara nuestro dispositivo. Para esta situaciones el kernel on the fly alloca major numbers con:
int alloc_chrdev_region(dev_t *dev, unsigned int firstminor, unsigned int count, char *name)
En esta funcion dev es un parametro de salida que cuando se completa la operacion tiene el primer numero del rango allocado.
Los device numbers son liberados con: void unregister_chrdev_region(dev_t first,unsigned int count)
Por lo general lo llamamos en la funcion de clean up (la marcada con __exit). Estas funciones allocan los device numbers para que los usuemos per ono le dicen nada al kernel acerca de que vamos a hacer con estos numeros. Antes de que una aplicacion de usuario pueda hacer uso de un device number, el driver tiene que conectarse con sus funciones internas que implementan las operacion del dispositivo. ALLOCACION dinamica de los major numbers:
ALgunos de los major device numbers son asignados a los dispositivos mas comunes (documentation/devices.txt). Por lo tanto podemos escoger para nuestro dispositivo un numero que paresca no estar usandose, o podemos allocar major numbers de manera dinamica. (para drivers nuevos siempre usamos alloc_chrdev_region). La desventaja de la allocacion dinamica es que no podemos crear los nodos del dispositivo por adelantado. En situaciones normales esto es rara vez un problema, ya que podemos leer los device numbers en /proc/devices. Entonces en vez de llamar solamente a insmod, llamamos a un script que llama a insmod, lee de /proc/devices y luego crea los nodos.
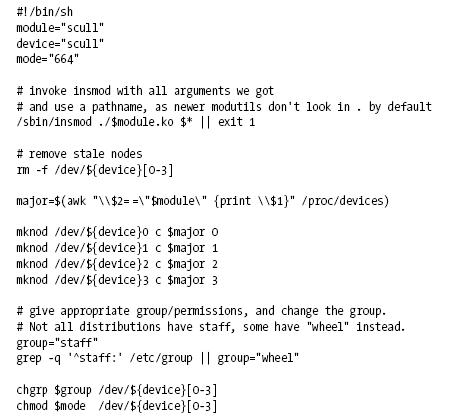
ALGUNAS ESTRUCTURAS DE DATOSLas operaciones fundamentales de los driver involucran 3 estructuras de datos del kernel llamadas: file_operations, file y inode.
FILE_OPERATIONS:Hasta ahora habiamos reservado algunos device numbers para usar, pero no los habiamos conectado con ninguna operacion de driver. Con la estructura file_operations logramos que un char driver haga esta conexion. Esta estructura (que esta definida en <linux/fs.h>) es una coleccion de punteros a fc. Cada archivo abierto (representado por una estructura file) es asociado con su propio set de funciones (mediante la inclusion de un campo llamado f_op que apunta a una estructura file_operations). Las operaciones estan a cargo de la implementacion de las system calls y por esto son llamadas open, read, write, close, etc. Podemos considerar a un archivo como a un objeto y a las funciones que operan sobre el los metodos.
La siguiente lista introduce las operaciones mas importantes que una aplicacion puede llamar sobre un dispositivo:
struct module *owner: no es una operacion, es un puntero al modulo que posee a la estructura. es usado para prevenir que el modulo sea descargado mientras las operaciones se siguen usando.
loff_t (llseek) (struct file, loff_t, int): este metodo es usado par acambiar la posicion actual de lectura/escritura en un archivo (la nueva posicion es un entero positivo, negativo si es error)
ssize_t (read) (struct file, char __user *, size_t, loff_t *): usado para recoger datos desde el dispositivo. Un resultado positivo nos indica cuantos bytes se leyeron.
ssize_t (aio_read) (struct kiocb, char __user* , size_t, loff_t*): indica una lectura asincrona, es decir, que la operacion puede no completarse antes de que la funcion termine. Si este metodo es NULL, todos los read se hacen sincronos.
ssize_t (write) (struct file , const char __user*, size_t, loff_t*): envia datos al dispositivo. El valor de retorno si es positivo, es la cantidad de datos que se escribieron exitosamente.
int (*open) (struct inode * , struct file *): esta es siempre la primera operacion realizada sobre el dispositivo.
int (ioctl) (struct inode, struct file*, unsigned int, unsigned long): esta llamada ofrece una manera de lidiar con comandos especificos de un dispositivo (formatear un disquette, abrir la lectora, etc, que no son de lectura y escritura). Adicionalmente, algunos pocos comonados ioctl son reconocidos por el kernel sin referirs a la tabla de fops.

LA ESTRUCTURA FILE: La estructura esta definida en <linux/fs.h> es la segunda en importancia de las estructuras de datos utilizadas en los device drivers. La estructura file representa un archivo abierto. Es creada por el kernel cuando se llama open y es pasada a todas las funciones que operan sobre el archivo hasta el ultimo close. La siguiente lista muestra los campos mas importantes de la struct file:
mode_t f_mode: identifica si los archivos son de lectura y escritura con una mascara: FMODE_READ y FMODE_WRITE.
loff_t f_pos: indica la posicion actual de lectura y/o escritura. El driver puede leer este valor si necesita saber la posicion en el archivo, pero por lo general, nunca deberia cambiarla. Read y Write deberian actualizar la posicion usando el puntero que reciben como ultimo argumento y no modificando directamente filp->f_pos. La excepcion a esto es el metodo llseek.
struct file_operations *f_op: son las operaciones asociadas al archivo. El valor de filp->f_op nunca es guardado por el kernel, por lo tanto podemos cambiar el comportamiento en runtime solo apuntando a otra estructura.
LA ESTRUCTURA INODE:
Es usada internamente po rle kernel par representar archivos. Es distinta a la estrucutra fule que representa un descriptor de un archivo abierto. Pueden haber muchas estrucutras file representando multiples descriptores abiertos sobre un solo archivo, pero todos ellos apuntan a una sola estructura inode. La estructura INODE contiene mucha informacion sobre el archivo. Pero solo 2 son de interes a la hora de escribir drivers:
dev_t i_rdev: para inodes que representan archivos de dispositivos, este campo contiene el actual numero de dispositivo.
struct cdev *i_cdev: cdev es la estrucutra interna del kernel que representa a un char device; este campo contiene un puntero a la estrucutra cuando el inode se refiere a un char device. Hay 2 macros para obtener el major y el minor number de un inode:
unsigned int imajor(struct inode *inode) unsigned int iminor(struct inode *inode) REGISTRACION DE CHAR DEVICES:
COmo ya vimos el kernel usa la estructura cdev para representar un char device internamente. Antes de que el kernel invoque nuestras operaciones, debemos allocar y registrar una o mas de una de estas estructuras. Para esto incluimos <linux/cdev.h>. Hay 2 maneras de allocar y inicializar una de estas estructuras. Por ejemplo si queremos obtener una standalone cdev structure en runtime lo hacemos con:
struct cdev *my_cdev=cdev_alloc(); my_cdev->ops=&my_fops;
Sin embargo a veces vamos a querer embeber una estrucutra cdev con una estructura especifica del dispositivo que nosotros hayamos llenado. En estos casos debemos inicializar la estrucutra que ya hemos allocado con:
void cdev_init(struct cdev * cdev, struct file_operations *fops);
Igualmente el campo owner de cdev tiene que ser seteado con THIS_MODULE.
Una vez que la estructura ha sido inicializada el paso final es avisarle al kernel.
int cdev_add(struct cdev *dev, dev_t num, unsigned int count)
Donde dev es la estructura cdev, num es el primer devibe number al que el dispositivo responde y count es el numero de debice number que debe ser asociado con el dispositivo.
Hay un par de cosas a tener en mente cuando usamos cdev_add. Lo primer es que puede fallar. Si devuelve un error code negativo, nuestro dispositivo no fue agregado al sistema. Si devuelve exitoso, en ese mismo momento nuestro dispositivo esta vivo y sus operaciones pueden ser llamadas por el kernel. Para remover un char device del sistema usamos:
void cdev_del(struct cdev *dev) METODOS OPEN Y RELEASE:
EL METODO OPEN: Para hacer cualquier cosa inicializamod en orden de estar preparados para futuras operaciones. En la mayoria de los drivers open tiene las siguientes tareas:
Verificar errores especificos de los dispositivos Inicializar el dispositivo si esta siendo abierto por primera vez Actualizar el puntro f_op Allocar y llenar cualquier estructura de datos para ser puesta en filp->private_data
Recordando el prototipo del metodo
int (*open) (struct inode *inode, struct file *filp):
Inode tiene la inofrmacion que necesitamos en la forma de su campo i_cdev que contiene la estructura cdev seteada antes. El probloema es que probablemente en la vida real queramos my_cdev strcutrue que contiene a la estrucutra cdev. Para esto recurrimos a un truquito llamado macro container_of (<linux/kernel.h>)
container_of(pointer, container_type, container_field); Este marcro toma el puntero a un campo (pointer) del tipo container_field con una estrucutra del tipo Container_type. y retorna un puntero a la estructura contenida.
Ejemplo en scull:
struct scull_dev *dev; dev=container_of(inode->i_cdev,strcut scull_dev, cdev); filp->private_data=dev;
EL METODO RELEASE:
El objetivo de release es lo contrario de open y debe realizar las siguientes tareas:
Desallocar todo lo que open alloco en filep->priv_data Apagar el dispositivo cuando ocurra el ultimo close
El metodo release mediante las llamada del metodo clouse pero solamente cuando el contado de las estructuras file llegue a 0. *en ese momento la estrucutra se destruye). Este contado es llavado por el kernel que cuenta cuantas veces una estructura file esta siendo usada.
USO DE MEMORIA:
2 funciones core definidas en: <linux/slab.h>
void *kmalloc(size_t size, int flags); void kfree(void *ptr);
una llamda a kamalloc trata de allocar size bytes de memoria; el resultado es un puntero a esa memoria o NULL si falla, El argumento flag es usado para describir como se debe allocar la memoria. (GFP_KERNEL)
METODOS READ Y WRITE:
Estos dos metodos realizan tareas similares,, copian datos de y hacia la aplicacion. Por esto sus prototipos son muy similares:
ssize_t read (struct file *filp, char __user *buff, size_t count, loff_t *offp);
ssize_t write(struct file *filp, const char __user *buff, size_t count, loff *offp);
filp es el file pointer, count es la cantidad de datos requeridos para transferir. Buff apunta al buffer del usuario que contiene los datos para ser escritos o un buffer vacio donde los datos leidos seran puestos. Funalmente offp es un puntero *del tipo long offset type) que nos indica la posicion en el archivo donde esta accediendo el usuario.
Hay que tener en cuenta que el argumento buff de los metodos read y write es un puntero a espacio de usuario. Por lo tanto no puede ser directamente referenciado por codigo del kernel. Hay un par de razsones para esta restriccion:
• Dependiendo en que arquitectura esta corriendo el driver, y como el kernel ha sido configurado, el puntero al espacio de usuario puede no ser valido cuando estamos corriendo en modo kernel, puede que esta direccion no tenga mapeo, o puede que apunte a otros datos random. • Aun si el puntero sifnifica lo mismo en espacio de kernel, la memoria del espacio de usuario es paginada (swapeable), y puede no encontrarse en RAM, cuando la sys call es hecha. Tratar de acceder directamente a la memoria de espacio de usuario puede generar un page fault, cosa que no esta permitida en el kernel. • El puntero en cuestion ha sido provisto por el usuario y puede ser buggy o malisioso.
Obiamente igual nuestro driver tiene que poder acceder al buffer de espacio de usuario para realizar su trabajo. Este acceso debe ser realizado siempre por funciones provistas por el kernel para que sea seguro. Estas funciones son: (<asm/uaccess.h>)
unsigned long copy_to_user(void __user to, const void from, unsigned long count);
unsigned long copy_from_user(void *to, const void __user *from, unsigned long count);
A pesar de que estas funciones se comportan como una funcion memcpy hay que tener un cuidado extra cuando accedemos al espacio de usuario desde el kernel. Ya que las paginas de usuario pueden no estar presentes en memoria y el sistema de memoria virtual puede poner el proceso a dormir. EL rol de estas funciones no esta limitado a copiar datos del espacio del usuario, sino tambien a revisar que el puntero en espacio de usuario sea valido. Si el puntero no es valido, no se copia nada. Y si se encuentra una direccion no valida durante la copia, solo una parte de los datos es copiada. En los dos casos el valor de retorno es la cantidad de datos copiados.
Entonces la tara del metodo read es copiar del dispositivo al espacio de usuaro (con copy_to_user). Y la tarea del metodo write es copiar datos del espacio de usuario al disposito (con copy_from_user).
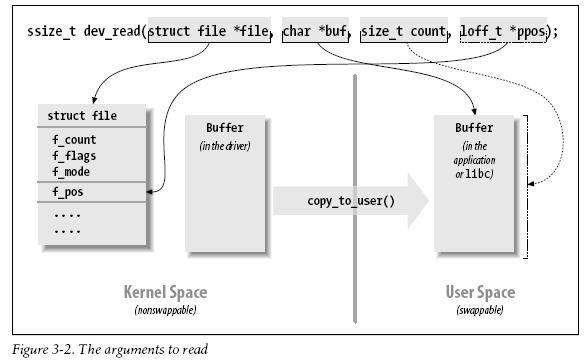
Cualquiera sea la cantidad de datos copiados, generalmente hay que actualizar la posicion donde nos encontramos en el archivo(*offp)
EL METODO READ:
el resultado de read es interpretado por la aplicacion que realizo la llamada:
- Si el valor es igual a count => todo OK!
- Si el valor es positivo pero menor a count => solo una parte se copio
- Si el valor es 0 => EOF
- Si el valor es negativo => se produjo un error
El metodo write es igual que el read
y hay que recordar que tenemos writes y read vectoriales