
Platform Engineering on Kubernetes in 2025
In October 2023, I published a book titled Platform Engineering on Kubernetes with Manning Publishing. The journey to write the book was quite an experience, and it still feels unreal that a project I started in 2020 was published as a book.
There is still much work to do in the platform engineering space, so I plan to start working on a new book edition towards the end of this year (2025).
I am writing this blog post because many things have happened since the book was published. I’ve structured this blog post in four phases to provide context on what I think are essential references to watch for the following years.
In the context of Platforms and Kubernetes and the cloud native ecosystem, I would like to classify the technical maturity of adopting different tools and practices. This classification helps me understand where organizations are, their priorities, and where and what gaps nobody fills.
For this classification, I identify four phases:
- Evaluate (aka PoCs)
- Adopt (running production workloads)
- Automate / Extend / Optimize your delivery pipelines
- Design your platform capabilities
In the context of evaluating, adopting, and building platforms on top of Kubernetes, we can classify organizations based on which of the following phases most resonate with their teams. The initial phase involves a lot of experimentation and learning.
Evaluate (aka PoCs)
Teams at this stage are overwhelmed with the fundamental challenges of adopting Kubernetes. Even if they know how to use Kubernetes, solving challenges around observability, security, and scalability can take a small team quite a while to master. At this stage, it is important to evaluate the organization as a whole to understand if the team working with Kubernetes is the first one or if there is previous expertise in-house.
Teams at this stage will need buy-in from the organization as a whole to be able to move faster and tackle these initial challenges. Nowadays, every vendor involved in selling Kubernetes services or managed Kubernetes offerings has a positioning statement about why your organization must adopt Kubernetes (for example IBM), this is quite handy, as back in the day, this involved multi-month worth of “friendly” conversations.
This is the way to start if you are in a non-Kubernetes savvy organization. You must solve these low-level challenges to demonstrate that you can run production workloads. When it was released back in 2021, the Kubernetes Maturity Model was very useful in helping organizations see what challenges they will be facing in their journey,
The platform engineering book, after a lot of deliberation, was written for an audience that was past this stage, but I keep always going back to this stage to evaluate how much we have made progress as an industry, as the Evaluate (aka PoC) phase is still too complicated for most teams to tackle effectively.
At this stage, teams will be looking at core technologies, including:
- Kubernetes
- Helm / Kustomize (other YAML manipulation tools)
- Containers (Docker, OCI)
- OpenTelemetry (Grafana, ELK stack, etc)
- Networking stacks like Cillium (more recently)
- Service Meshes (rabbit hole)
At this stage, teams quickly realize that Kubernetes is not the end goal, and there will be a lot of hard decisions to make along the adoption journey.
Adopt (running production workloads)
At this point, organizations are running production workloads on Kubernetes and have multiple Kubernetes-savvy teams collaborating in different aspects of the entire software delivery pipeline.
At this stage, there is a broad understanding of how Kubernetes works, and a set of tools has been adopted to facilitate tasks. Some hard choices have been made, and processes are in place to troubleshoot when things go wrong.
Development teams at this stage are familiar with containers as their applications are packaged and executed inside containers. They are now familiar with issues related to containerization, standard practices on how to parameterize applications, and a somewhat clear understanding of how their applications are scaled for production workloads.
When organizations hit this stage, most of the software delivery process is manual and error-prone. Smaller organizations (“we have only 5 Kubernetes clusters”) tend to opt for simplifying operations until they fully grasp the complexity of the end-to-end process. It is common to see topics like observability being delegated to expensive cloud services, just because tackling all issues at once is way too much.
At this stage, teams will be evaluating technologies, including:
- Argo CD / Flux CD for GitOps automation
- Harbor (Container registries and container scanners)
- Terraform / Pulumi for provisioning and managing cloud resources
- Managed services to delegate existing challenges
When I was writing the book, it was common to see organizations building their solutions in-house to solve these challenges. One of the main reasons for writing the book was to show some of these tools applied in a context and provide the reader with hands-on experiences to have more informed discussions with their teammates about the problems and use cases these tools were designed to solve. This leads me to the next phase: Automate / Extend / Optimize.
Automate / Extend / Optimize your delivery pipelines
In the book, I left the topic of writing your own Kubernetes controller out, mostly because it is a big topic but also because there are tons of resources on how to do this. Coming with a 15+ of experience in Open Source, I wanted to show people how to evaluate the tools available in the ecosystem and extend them when necessary.
Unfortunately, reality tells me that most organizations will make hard choices to create their own extensions, mostly to glue other tools that are not aligned with the solutions that the organization needs.
This stage is all about optimization and automation. Organizations know where the bottlenecks are, and most investments are made to reduce costs and optimize how tools are used to reduce these frictions.
Compared with the previous stage, hard choices had been made on top of Kubernetes. You now have a stack of tools your teams must deal with. It is common to see organizations, as a result of a top-down decision, adopt tools like Red Hat Openshift, which not only provides a stack of tools that have been already integrated but also services around it.
In the book, I use, as an example, the creation of a development environment. This process needs to be fully automated, and it involves a set of tools that need to be glued together to perform a very concrete end-to-end use case.
It is common to see what I consider the early discussion about platform engineering at this stage, mostly because teams are building integrations that they want to hide behind a new high-level set of APIs. Behind these APIs, entire flows are automated, so teams can focus on consuming APIs instead of choosing and gluing different tools together. Conformance and policy enforcement become priorities as standards across teams must be set to provide consistency.
Teams at this stage will start looking into more complex tools like:
- Crossplane for API creation and resource aggregation
- vcluster for reducing costs to enable teams with cheaper clusters
- Kubevela
- OAM (Open Application Model) specification
- Or more specialized tools like Kubeflow / KServe, I like having conversations about the for ML/AI workloads
- Policy tools: Kyverno / OPA
Design your platform capabilities
Bringing organizational and technical change together becomes important if you want to promote serious platform engineering initiatives. The platform engineering maturity model published by the CNCF can help us evaluate organizational maturity regarding platform engineering practices.
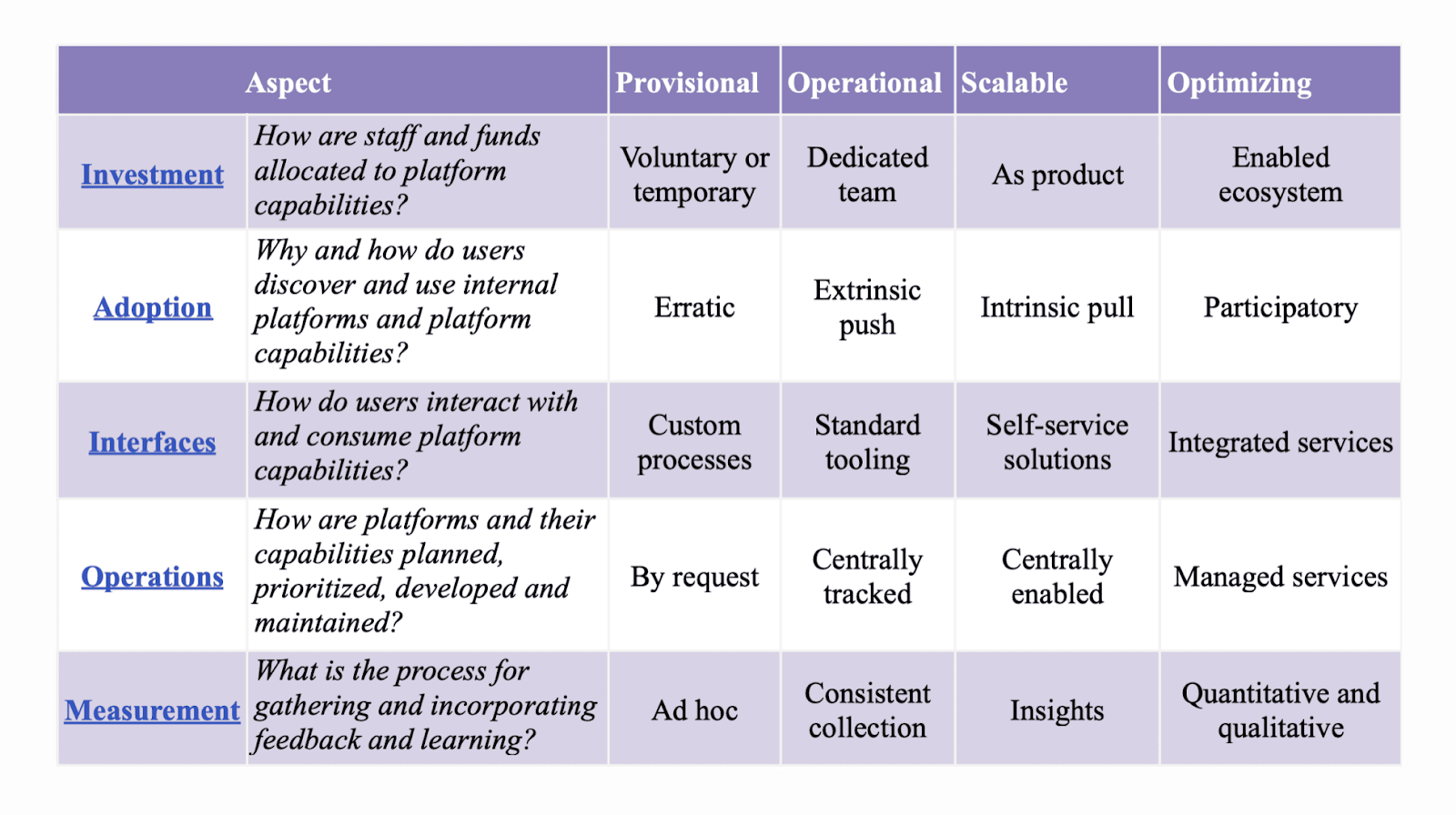
This is a significant step forward in understanding better where organizations are in their platform journeys. However, I still evaluate their technical challenges and priorities to know where these companies are in their platform engineering journey.
Organizations at this stage tend to prioritize hiding low-level details, provide centralized access to resources, and start defining “experiences”, being “developer experiences” a new trend in our industry. In my opinion, this is, again, a great sign that we are going in the right direction. Kubernetes and the cloud native ecosystem are no longer about running applications but also about getting closer to developers producing code that needs to be shipped to customers.
In this stage, I like having conversations about the tools platform teams can use to provide high-level features to their consuming teams. For example:
- Feature flagging with OpenFeature
- Abstracting away infrastructure complexity with Dapr
- Enabling teams to experiment by enabling different release strategies (A/B testing, traffic splitting, canary deployments) with Argo Rollouts or Knative Serving
- Unified access to a service catalog, golden paths (scaffolding) and connecting departments with a single portal with Backstage
There has been a push for consolidation in the entire cloud native space, and while innovation is still happening, a few projects have been raised to be the clear winners. Besides which projects are doing well and not doing so well (running out of funds), consolidation stories like CNOE (cloud native operational excellence) and the BACK stack show clear signs that today, all that matters is to have a strong ecosystem play.
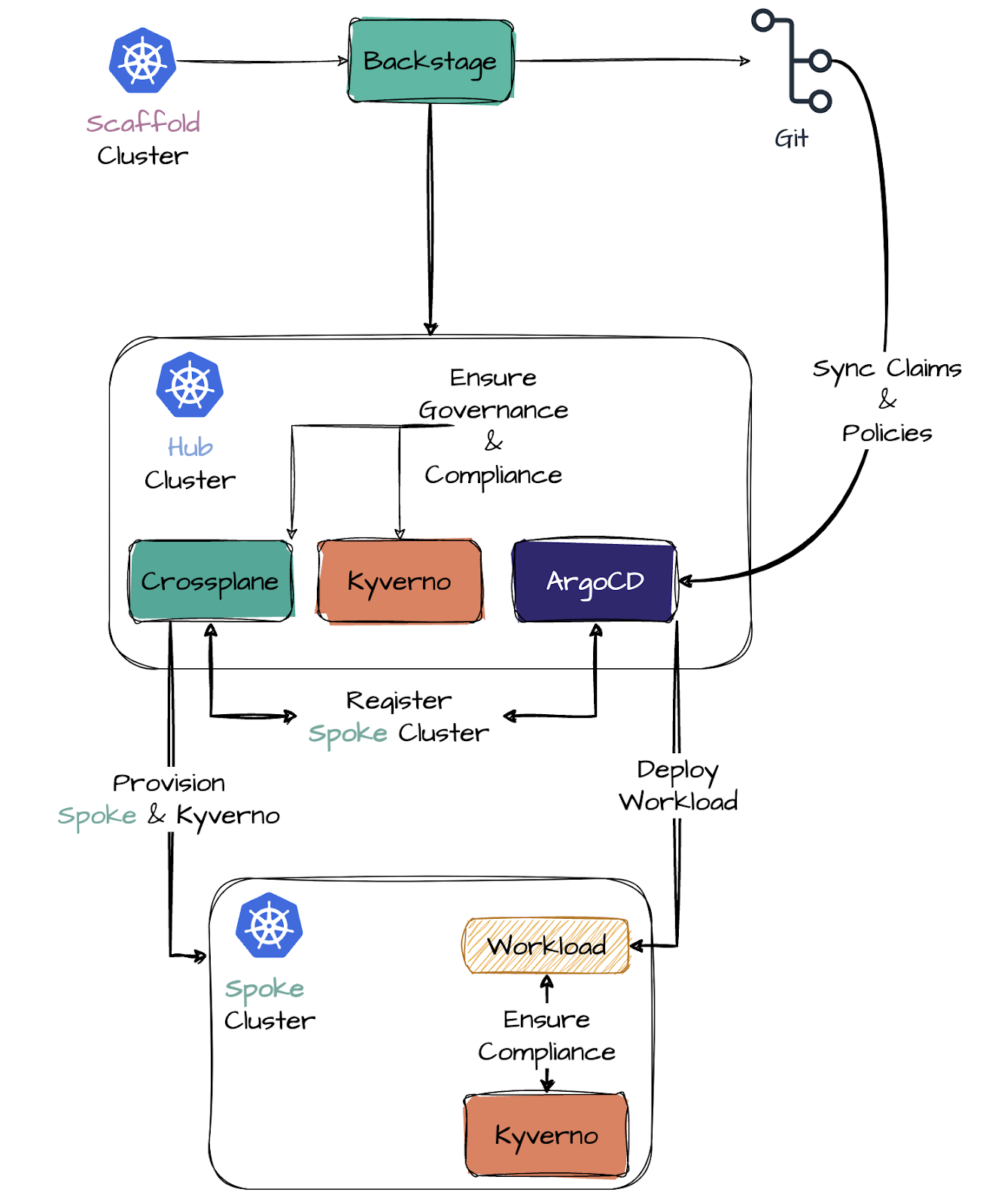
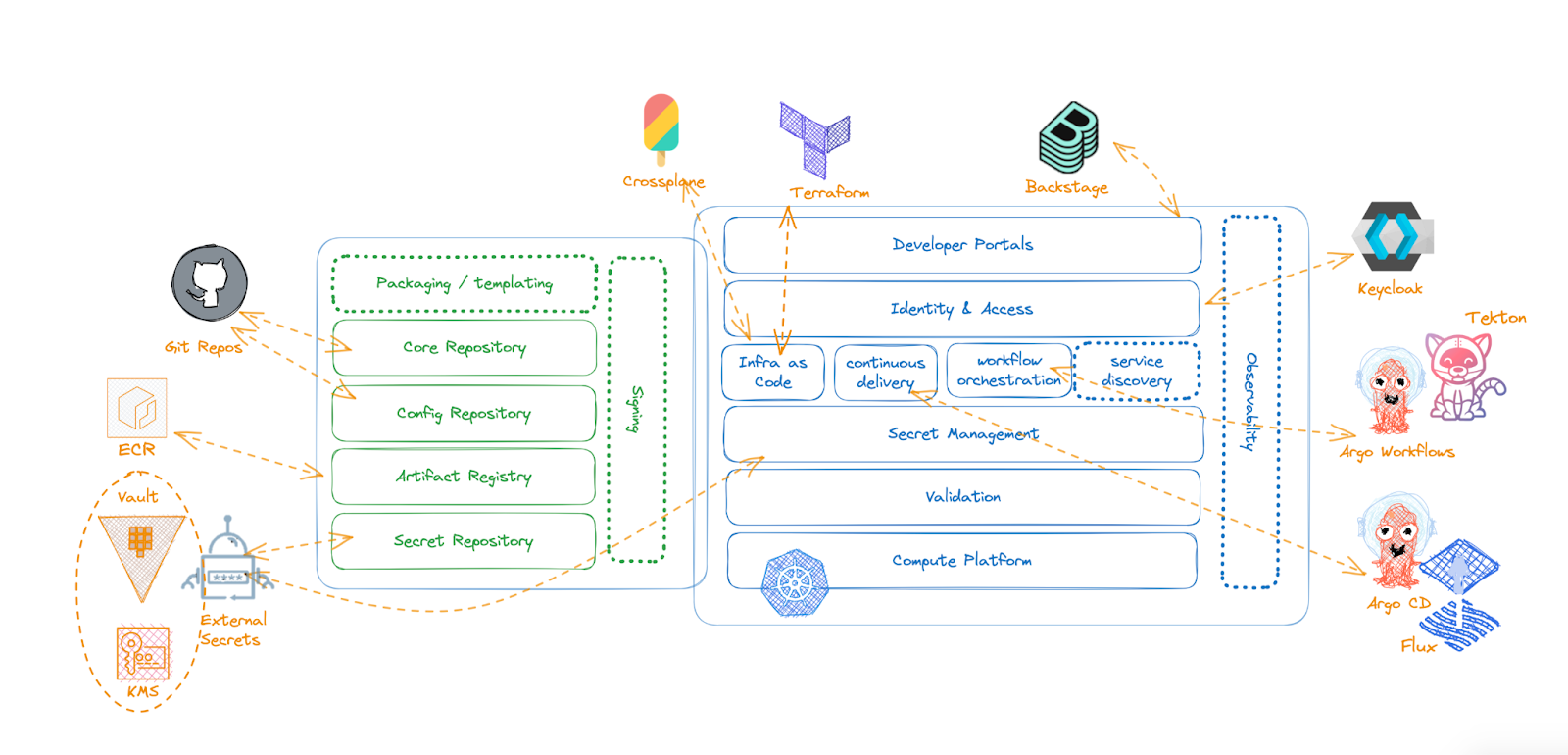
The fantastic activity around the Backstage project shows the need for unification, but most importantly, highlights that the fragmentation of tools in this space is too much to handle, hence, tools to aggregate and provide consolidated experiences are in high demand.
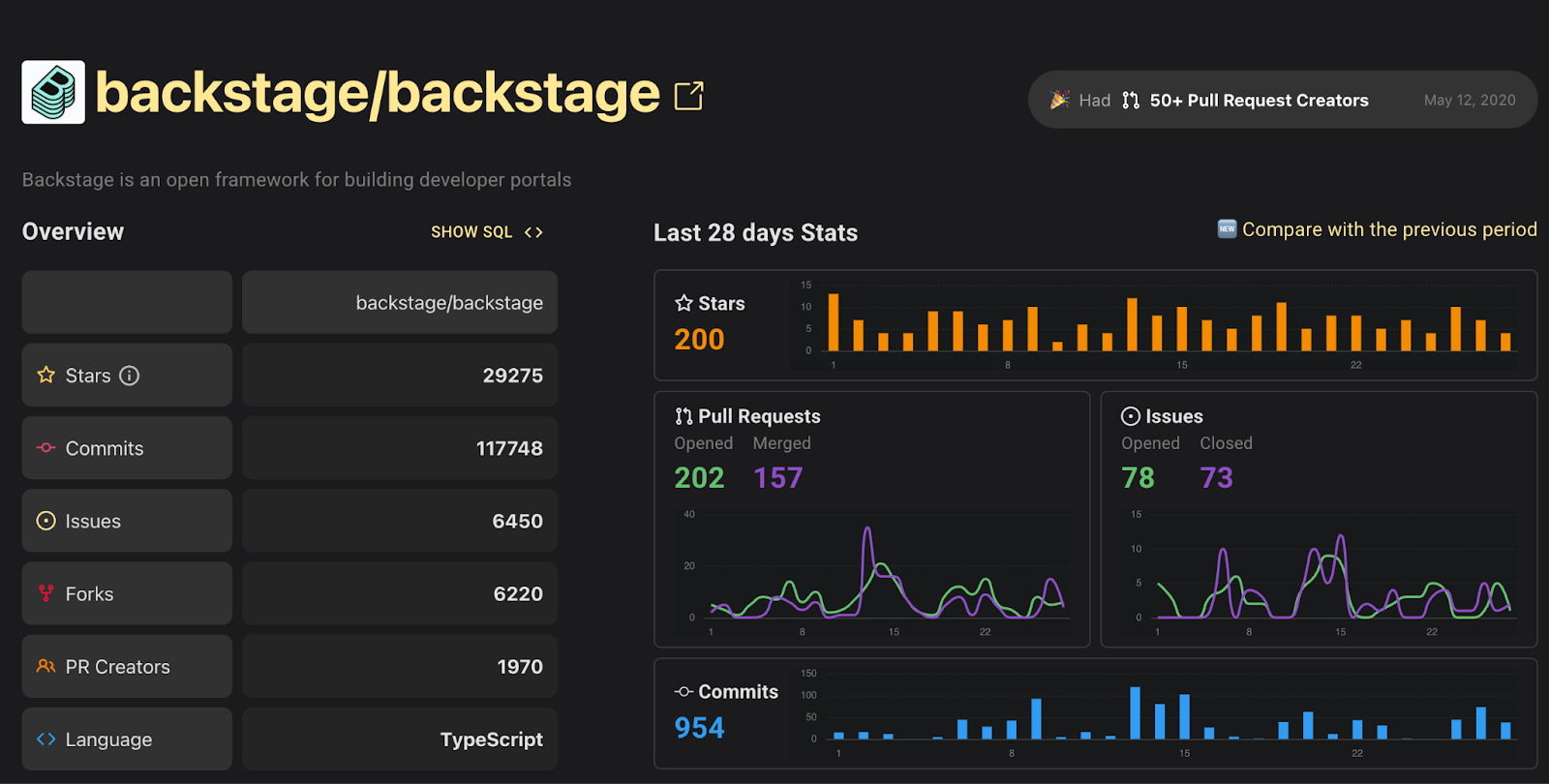
Companies like Red Hat, investing in tools like Backstage with their Red Hat Developer Hub brings confidence to the space and generates collaborations across vendors to provide plugins that play nicely with the entire ecosystem.
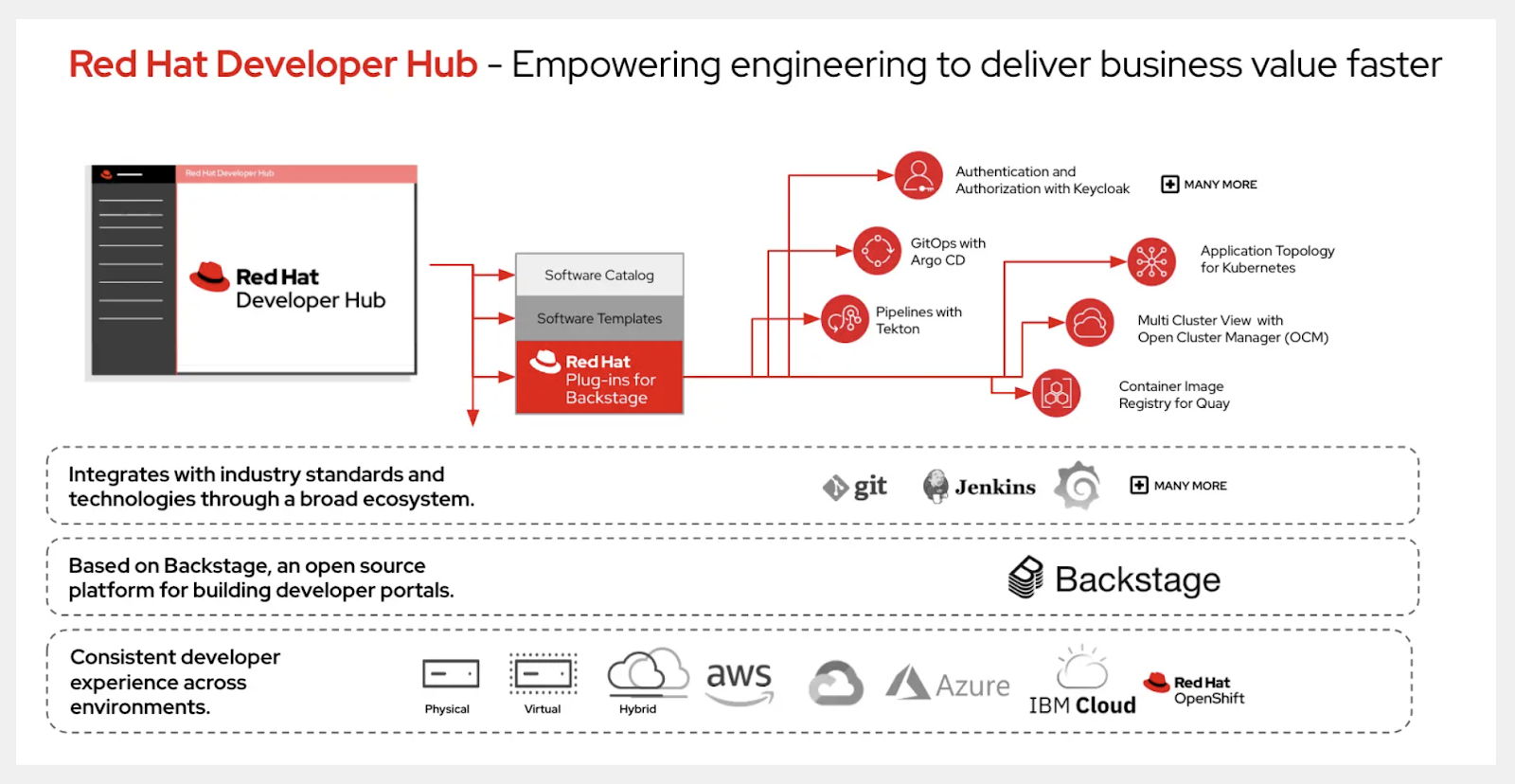
On the developer experience front, Podmandevelopers is also heading in the right direction. Now donated to CNCF, it demonstrates a much more coherent story than what we have seen from Docker, a company that refused Kubernetes for a long time. Podman provides a much integrated solution from developer frameworks, debugging tools on Kubernetes, and integrations with LLMs tooling.
On a different angle, with the creation of the App Development Working Group last year, we hope to be able to bring developers closer to this space, because there is still a big gap. We need to bring developers closer if we want to build platforms that transform the way organizations ship software. We cannot leave developers out of the equation or treat them as end users, where they don’t have choices. Check our presentation with Abby Bangser at KCD UK about this topic: “When platform teams meet developers”.
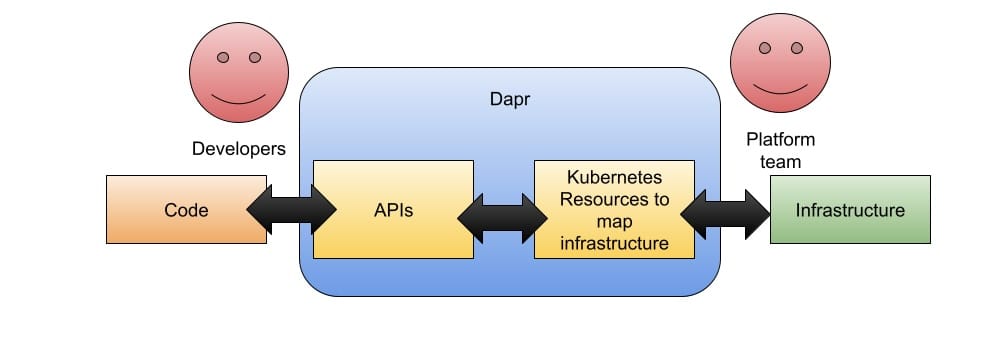
In this context, I feel quite optimistic to be working for a company like Diagrid and working for the Dapr project, as we are reaching a point where we are in high demand for tools that work in this very complex ecosystem and provide abstractions that can be used to enable teams with well-defined APIs that implement well-known cloud-native patterns.
So what’s next
This year has started at full speed. I didn’t even have time to do last year's recap, but all I can say is that I am looking forward to seeing how KubeCon EU here in London turns up. With new platform certifications in the pipeline, I expect this to help us understand where companies are and the main challenges that they are facing.
This year, for the first time, we will have a fully dedicated KubeCon track targeting application developers. While it is far from perfect, I hope this space attracts new communities and brings developers closer to the cloud native space.

There is still much work to do to bring platform teams closer to developers, as we stated in this presentation last year at KCD UK with Abby Bangser. It is fundamental for platform teams to meet developers where they are and solve challenges that are slowing down the software delivery process.
Developer experiences is a topic that I am keeping an eye on in this space after seeing the big push for tools like Backstage. The next step is to define and design how developers interact with all these tools. Scaffolding and basic golden paths are not enough for real-life projects, so I expect an evolution of the tooling in that space.
Jumping to more infrastructure-centric challenges, it was interesting to see at KubeCon NA the highlight of projects like Kueue, KCP, and Kubernetes Workspaces. Solving challenges and specific use cases across multiple clusters requires very specific solutions. Kueue being highlighted in one of the keynotes made me realize that a whole new breed of projects will pop up to solve this kind of specific challenge.

AI/ML, what can I say about this? It is a wild space where we must wait for consolidation, but hope remains. At KubeCon NA, we saw progress in ensuring we can reliably run AI/ML workloads on Kubernetes as first-class citizens. “We can schedule workloads based on their hardware requirements with ease”. Having DRA(Dynamic Resource allocation) for GPUs helps us to keep pushing for Kubernetes to be the de facto base layer to build solid platforms that run all kinds of workloads.
Looking at announcements, such as the Solo AI Gateway , the Envoy AI Gateway and the Dapr Conversation API, makes me think that most of the challenges ahead are integration challenges.

AI/ML and LLMs bring new challenges, not only for execution but for integrating new features with our existing applications.
This year, you must prepare for AI agents and, more importantly, frameworks to create AI agents that can help platform teams and developers automate more complex tasks. Keep an eye on the Dapr project for more news about this, as accessing LLMs is just one part of the equation.
My big hope for this year and next is to bring more companies together to create more stacks and shared blueprints on how all these tools can be combined so new organizations have an easier journey than those ahead of the game.
I hope that we bring developers closer to this vibrant ecosystem. Without a strong developer presence, the focus will remain on infrastructure, relegating developer experiences for later and not speeding up their software delivery cycles.
I look forward to crossing paths with all of you this year. I will do my best to share my whereabouts as my year progresses. Have a fantastic platform engineering journey in 2025!
As always if you have any questions or you want to reach out drop me a message on my social networks @Salaboy.