
The Challenges of Platform Building on Top of Kubernetes 3/4
TLTR: Crafting friendly and simple Platform APIs is key to driving the adoption of your internal development platforms. Some tools allow you to extend the Kubernetes APIs to serve as your Platform APIs while exposing higher-level resources to enable teams to consume complex infrastructure using a self-service approach. Tools like Crossplane, MetaController, and Kratix allow you to extend Kubernetes without writing Custom Kubernetes Controllers.
Ok, so we have covered some projects to build platforms and how these tools can interact to provision, manage and install tools that we need for our development teams to be productive. Check my two previous blog posts if you haven’t done so [1], [2]. In this blog post, I cover an essential part that cannot be left out when building platforms, the Platform APIs, and the importance of making these APIs accessible to the right teams.
If your platform does great things, but nobody can use it, it wastes everyone's time. These APIs are a core component of the Platform experience that you will deliver to your application development teams. Hence, having the right tools and a deep understanding of how to craft these APIs is fundamental to enabling developers to consume your platform and other tools to add automation on top of it.
You want your APIs to be specific enough for your consumers to get what they need and as standard as possible to enable tools in the ecosystem to integrate with and maybe even extend them. If you fail in any of these two angles, then you are digging your own grave.
Because we are talking about Kubernetes tools and this blog post is about APIs, we will need to talk about CRDs (Custom Resource Definitions - Kubernetes APIs extension mechanism) and the components you need to build to work with these CRDs. We will also discuss working with multiple CRDs, your own and third-party ones, and how they play together.
APIs are about abstractions, which are critical for our conversation here. The abstractions for my company will not be the same as those for your company, as we are probably trying to solve different problems by creating solutions for different audiences. Having said this, most companies will have common challenges, such as building and releasing their software, making it secure and efficient while keeping an eye on costs. For these more general and not business-specific challenges, you should look at the CNCF landscape, as many companies and communities are sharing tools to solve these industry-shared challenges.
Let’s start with a quick review of what it takes to extend Kubernetes, in which situations we might be interested in doing so, and when we shouldn’t.
Extending Kubernetes, being Kubernetes-native
Ok, so I will not describe how Custom Resource Definitions and Custom Resources work on Kubernetes, as there are already enough articles about that topic ([1], [2], [3] to link a few). Still, I thought about mentioning some fundamental aspects of what to expect when extending Kubernetes.
When you work with vanilla Kubernetes and use built-in resources (Deployments, Services, Ingresses, etc.), you use the Kubernetes basic building blocks. Kubernetes provides controllers to reconcile all built-in resources, knowing what to do when creating the user creates a new Deployment, Service, ConfigMap, or any other supported resource.
Each resource defines an API, meaning you can configure these resources differently depending on how you want them to behave. Each built-in resource is defined using the OpenAPI v3 spec, which allows us to create clients for these APIs using different programming languages in an automated way.
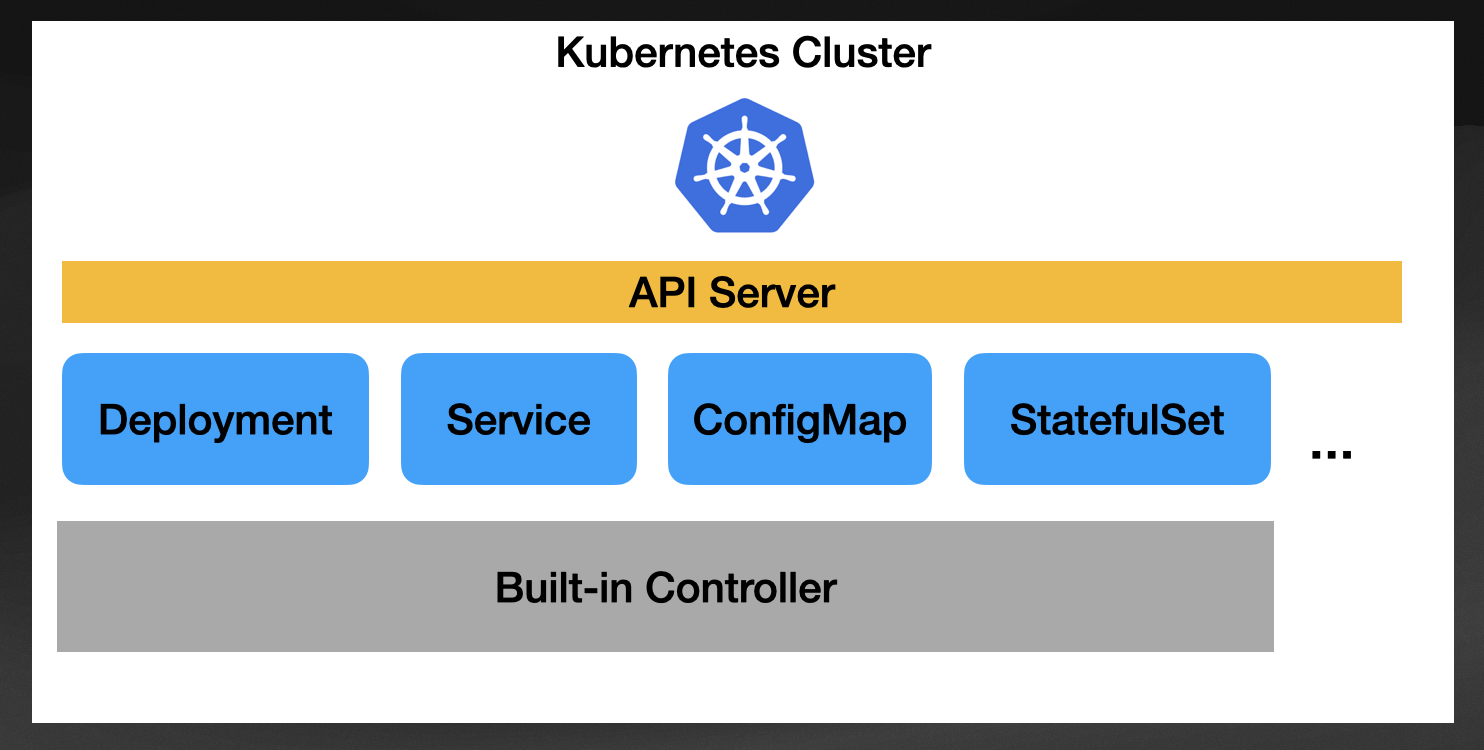
One big reason for the Kubernetes ecosystem's growth and success is that you have Kubernetes Clients (SDKs) in every major programming language, allowing you to generate these built-in resources programmatically. This allows automation tools to be built in different programming languages, reusing other ecosystems outside the Kubernetes space.
While you can go a long way by using these built-in resources, it is quite a natural next step to group them and build more complex functionality by combining and aggregating them. That’s exactly where one of the main extension points of Kubernetes shines.
Suppose you are building a Platform on top of Kubernetes and want to introduce a new resource type. You can call that “MyContinousIntegrationPipeline” or “MyComplexApplication” which encapsulates Kubernetes resources such as Deployments, Ingress, Services, and ConfigMaps together into a higher-level resource. The purpose of this new higher-level resource is that you can monitor and manage a collection of related and dependent resources as a single unit. Because you are aggregating different behaviors (built-in Kubernetes resources), you must write (and release, maintain, upgrade, etc.) a custom Kubernetes controller.
This custom controller will know how to reconcile your new Custom Resource type, so every time you create a new resource of your “MyComplexApplication” the controller will be notified to create, modify, and delete other Kubernetes resources to make your “MyComplexApplication” alive and healthy.
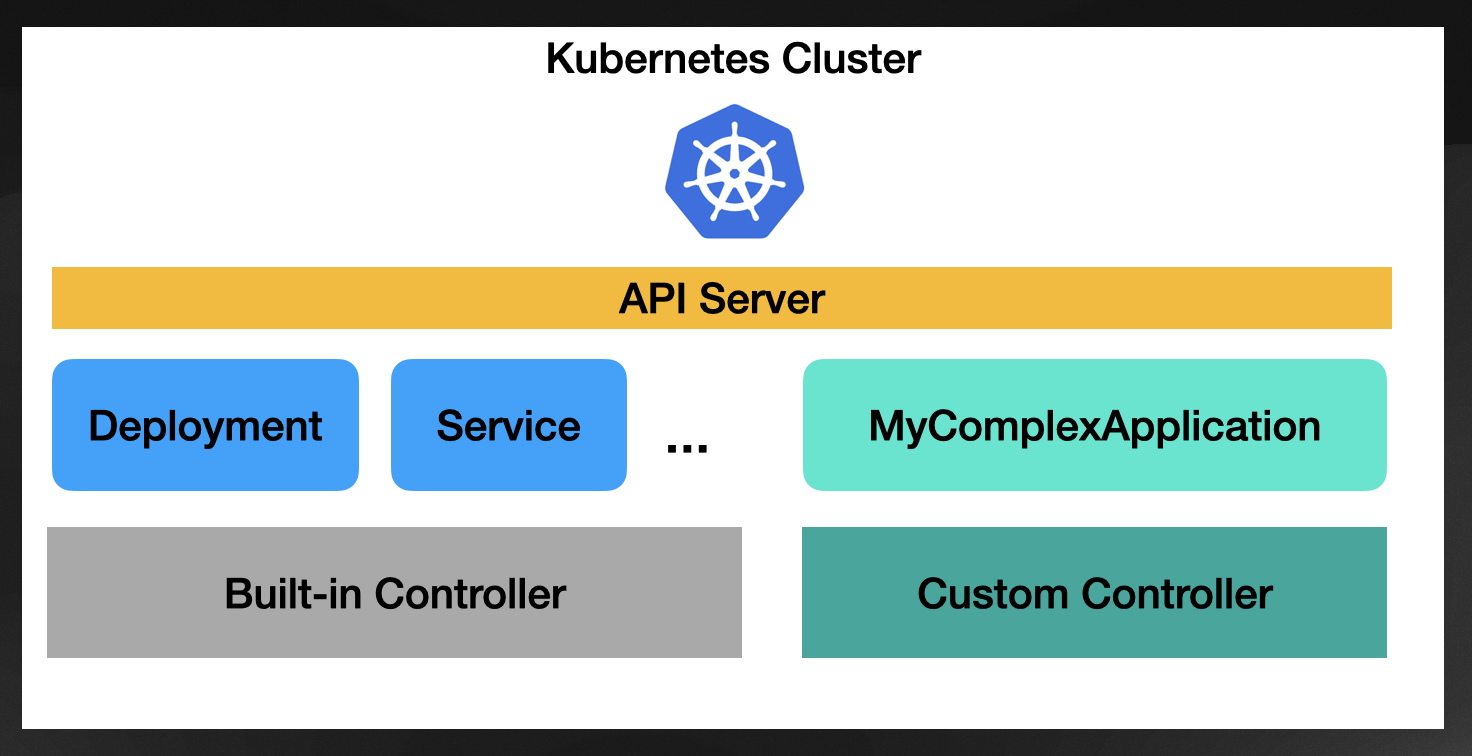
If you are building this kind of Custom Resource that aggregates a bunch of Kubernetes resources, the logic will be about aggregating the state of the “managed” resources.
Kubernetes comes with a mechanism that allows you to group resources by stamping an owner reference (or parent resource) to each resource you create. For this example, “MyComplexApplication” resource will be the owner of whatever resource gets created when the “MyComplexApplication” reconciliation happens. Imagine that you create two Deployments, a Service and an Ingress, all these resources will have the same owner, in this case, the “MyComplexApplication” resource, and they will be managed together; that means that by default, if you delete the “MyComplexApplication” resource, the children will be deleted as the existence of these resources were linked to the parent (owner).
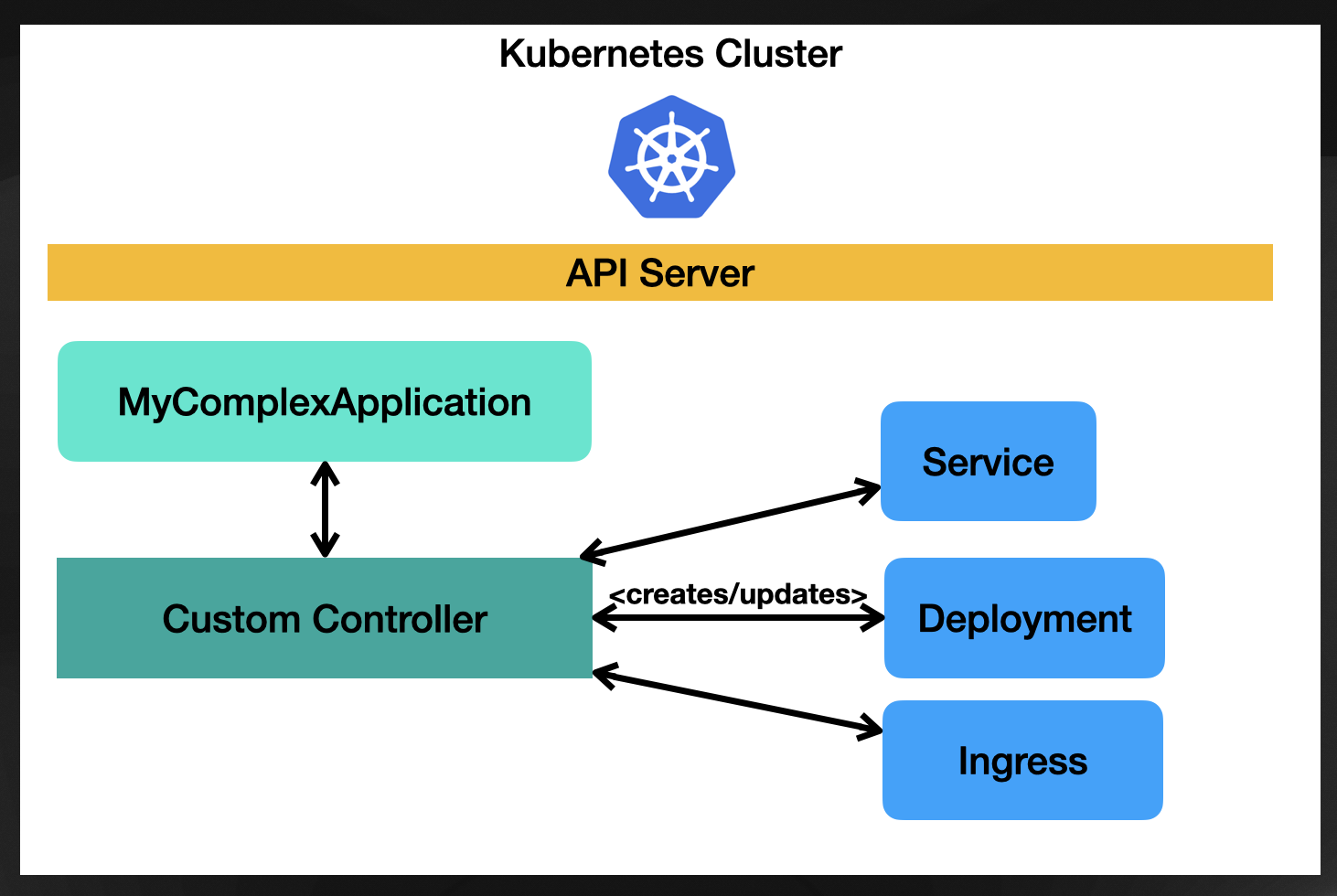
This way of grouping resources allows you to hide all the complexities and subtleties about Deployments, Services, and Ingress, as your “MyComplexApplication” can decide which properties to expose. If it exposes many properties, it will be more complicated to use, as you, as a user, will need to know how to fill in all these details. If it exposes only a few, the amount of knowledge the user will need to create “MyComplexApplication” resources is drastically reduced.
And this is a very powerful idea. We have defined a new API (MyComplexApplication) that hides all the internal resources created and allows users to create new MyComplexApplications to specify the relevant parameters. As with every good abstraction, this also allows developers to write the reconciliation logic to change the internal resources being created and their configurations without pushing the ones creating the resources to learn about what is happening under the hood.
Another common scenario that doesn’t involve aggregating built-in resources is to provide integration between Kubernetes and other APIs (it can be external or running inside Kubernetes). For this use case, the controller contains the logic for interacting with these APIs to provide a Kubernetes-native way to work with these APIs. To follow the example introduced before, imagine that your “MyComplexApplication” runs on a mainframe, and by using some scripts, you can provision new instances of these applications.
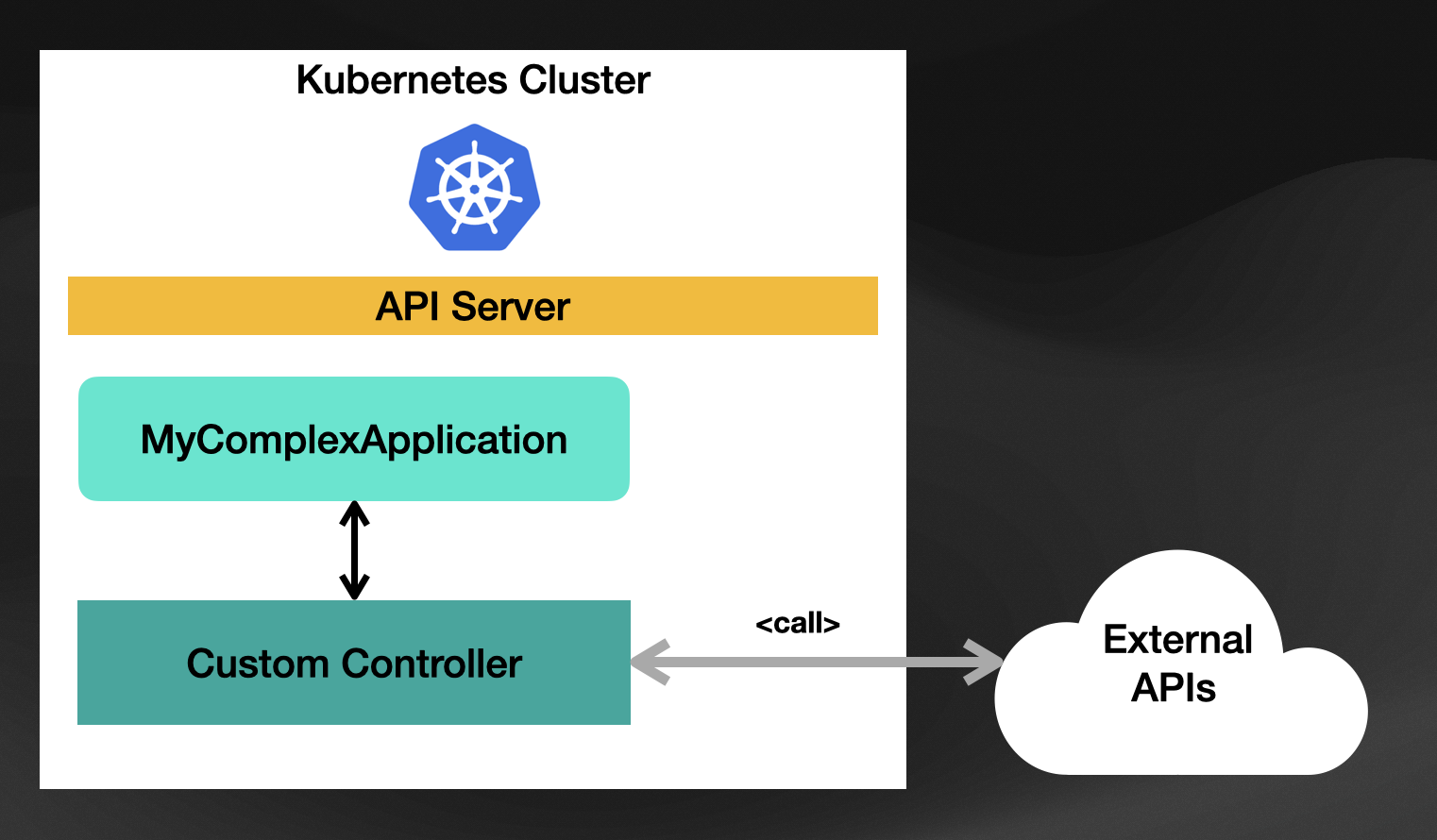
For this example, the controller will need to include the logic of calling these scripts on the mainframe to create new instances of the application every time a new “MyComplexApplication” resource is created inside our Kubernetes Cluster. The controller will also need to know how to query for state so it can keep monitoring the mainframe to see if the applications are there, running, and healthy.
By extending Kubernetes in this way, we are creating the building blocks for a platform that achieves two things:
- Provide complex functionality to tackle the challenges that our company is trying to solve. This is achieved by creating new resource types which follow the OpenAPI specification, allowing existing tools to connect, integrate and automate other tasks by creating and manipulating these new resources.
- Reduce the cognitive load of learning Kubernetes built-in blocks. Custom controllers take the burden of managing Kubernetes' built-in resources or external systems to hide away their complexity.
In the next section, I wanted to focus on the challenges that I’ve seen people facing when extending Kubernetes and why a new breed of projects and mechanisms are being created to facilitate the creation of platforms on top of Kubernetes without pushing teams to learn and master all the intricate details of extending Kubernetes.
Extending Kubernetes, you should NOT!
Ok, the title is a bit too much on purpose, but believe me, you shouldn’t be extending Kubernetes unless you have a very, very, very good reason to do it. Here are four points to consider before extending Kubernetes by creating CRDs and custom controllers:
- Check the CNCF landscape: Suppose you are trying to extend Kubernetes to do something that is not very specific to your company, like Continuous Integration tasks, Machine Learning workflows, Event-Driven Architectures, etc. In that case, some other team must be already working on that. Before building your custom extension, try to research the ecosystem to see if there is a solution that fits your use case and then join that initiative.
- Choose your tools wisely: for quite some time, if you wanted to extend Kubernetes, you used tools like KubeBuilder and/or Operator Framework. These tools are written in Go, and you must learn “Go” to use them. It took quite some time to have similar tools in languages like Java and Python, and that is mainly because it is not an easy task to write components for distributed systems. There are a lot of subtleties on how these components should work, be scaled up, and be good citizens in a distributed architecture.
- Maintenance is hard: even if you have the right tools for the job, you will need to maintain and update these components in the long run. You will rely on the engineers that designed these components to stay around for these components to stay up to date and work as expected in the long run. If they use a different programming language and tools to build and release these components that are not what your other teams are using, there is a high risk associated with the long-term support of these components. I haven’t touched on that because Kubernetes controllers must interact with the Kubernetes API. They become very security-sensitive components. Tools like KubeBuilder automatically generate some default RBAC objects, but it is your responsibility from then on.
- Kubernetes controllers are usually cluster-scoped: controllers are usually written to target a single Kubernetes cluster. That is to manage resources that are inside a Kubernetes cluster. As I covered in my previous blog post, if we are building platforms, we will not be talking about a single cluster. Hence you might find yourself installing, managing, and upgrading the same custom Kubernetes controller in multiple Kubernetes clusters.
Besides these considerations, people keep extending Kubernetes, and I see two main reasons to do that:
- Provide a simplified API for very specific use cases
- Build complex functionality that is not supported out of the box, this includes gluing existing tools together
But how about we can achieve these two things without the need to write custom Kubernetes controllers?
Let’s look at some tools that build these capabilities to get the benefits of controllers without the hassle of writing and maintaining these complex components. We will be looking at the following projects and mechanisms:
- Crossplane compositions as a way to link a new Custom Resource Definition to a collection of cloud resources
- MetaController as a way to extend Kubernetes without writing Kubernetes controllers
- Kratix for platform building, multi clusters, and tools agnostic approach to glue things together.
CRDs and Crossplane Compositions
With Crossplane, you can extend Kubernetes with your own Custom resource types but without writing Kubernetes Controllers, and that is a BIG thing, in my opinion. You can focus on defining custom resources that make sense to your teams and then declaratively define what the resource is responsible for.
The way to define and link resources in Crossplane is by using Crossplane Compositions (composite resources). With composite resources, you can define a set of resources that will be created and monitored for each custom resource you create.

In this figure, we can see that now our “MyComplexApplication” resource will be managed by Crossplane (Crossplane controller that we installed when we installed Crossplane), which will trigger a Composition of 3 cloud resources: a database, a Kubernetes Cluster, and a bucket for this example.
“MyComplexApplication” CRD defines which properties to expose for users to create these resources and defines which parameters are required and which are not. If you want to take it to an extreme, you can create a resource without setting any properties. The composition will create the associated resources with all the default parameters in such cases. In other words, by creating a new instance of “MyComplexApplication” resource without setting any properties, you have created a database, Kubernetes cluster and a bucket using all the default configurations. Now the users creating “MyComplexApplications” doesn’t need to know anything about databases, clusters, or buckets.
If you want to give your teams more control, you can decide which properties to expose make sense to them. Maybe they want to define the database size or where in which region the Kubernetes cluster needs to be created. At the end of the day, the CRD that you define (in this case, the MyComplexApplication CRD) is the API that users will see and use.
I really like to think about CRDs as Forms in the management console. If you look at how you create Kubernetes Clusters in GCP, for example, you will see a page like this:
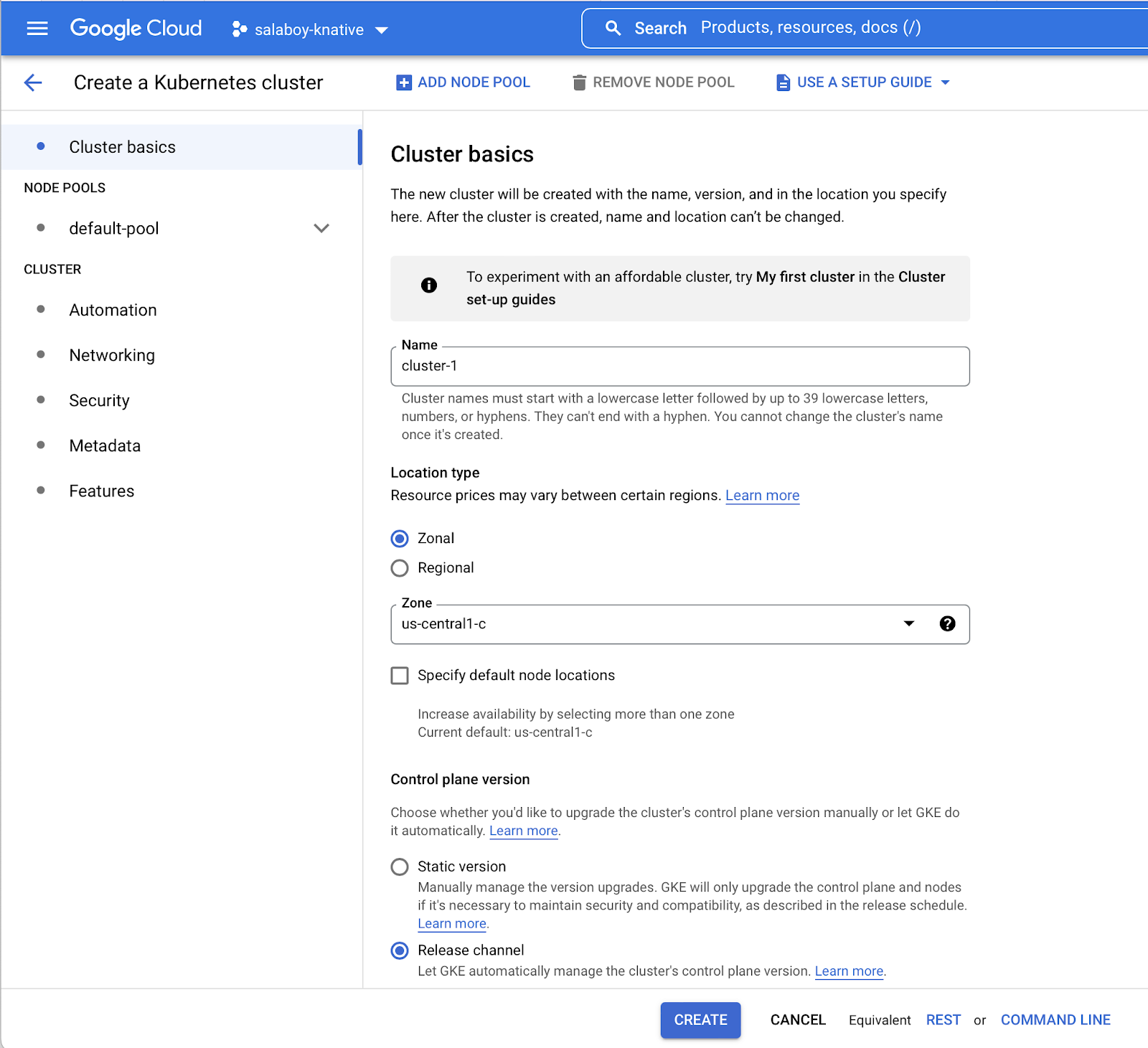
Here you can hit the Create button immediately and a cluster will be created using the defaults. If you want to fine-tune some of the cluster details, you can do that too, and as you can see, different properties are grouped under different categories to help the user to find the properties that they are looking for. If you check the Crossplane CRD for creating Cluster on GCP you will find that the CRD encodes this form representation into a Kubernetes resource.
Another important aspect is about who the audience is for that form/CRD. You must consider the target audience’s expertise and use cases when deciding which properties to expose. Google Cloud Kubernetes Engine makes it really simple for someone to create a cluster without the need to know all the internals, you can simply hit Create, and you will have a cluster. You want to ensure that your CRDs work that way for your target users.
Once you have your API/CRD/Form information defined and you link this to a Crossplane Composition, the composition is in charge of aggregating the state of all the associated resources.
Without going into much detail on how this works, Crossplane provides a generic controller that will take a composition, create and manage the resources that are defined inside and report an aggregated status to the custom resource that you have associated with the composition.
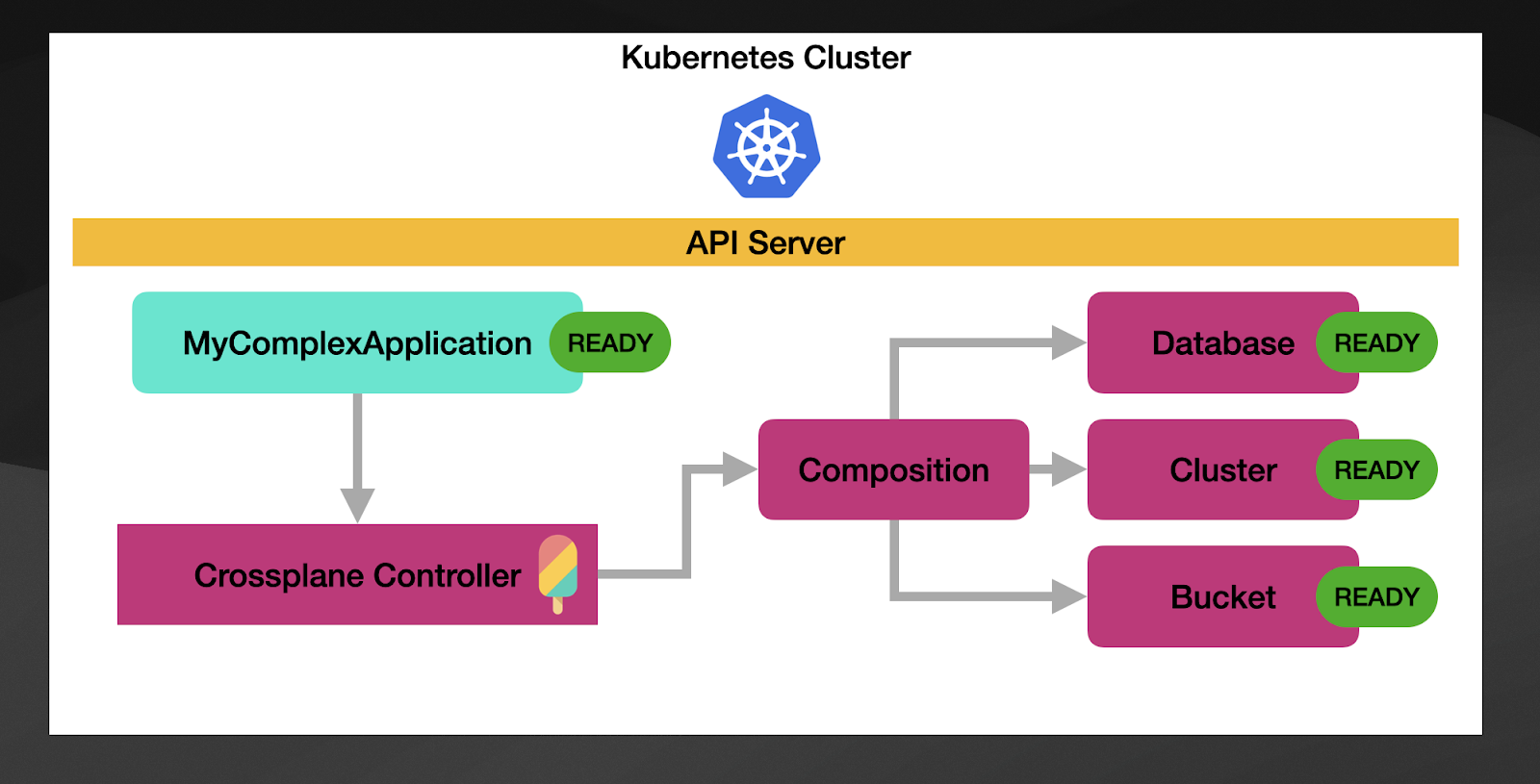
The composition controller will check on the resources managed by the composition, check their state. If they all are healthy (READY), the parent resource, in this case, “MyComplexApplication” will be marked as ready.
If one of these resources goes down, the parent resource will be also change status.
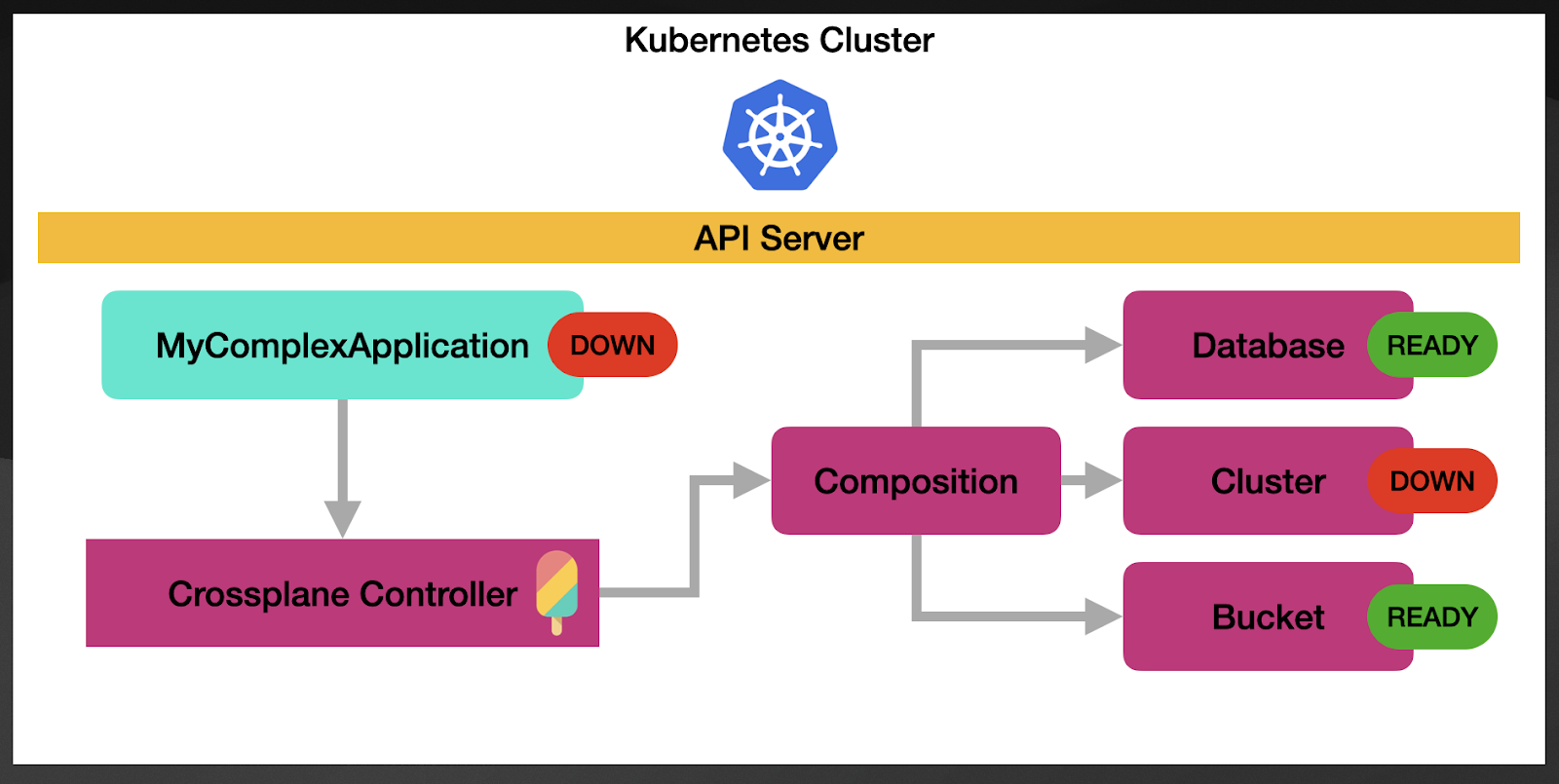
The aggregation happens by using the Kubernetes reconciliation cycles. This means that each of the resources created by the composition is constantly monitored by Crossplane to check their state. This is particularly important to show that at all times, users of MyComplexApplication have an up-to-date status of all the resources needed for this application to run.
Because this is a generic behavior implemented by Crossplane controllers, and because this kind of orchestration between resources can be implemented without writing our own controllers, it makes a lot of sense for Crossplane to keep showing up as a must tool for building platforms.
But wait, there are some challenges that I don’t have the time to cover here, but I’ve touched on a previous blog post that is still relevant, and you can check it out here. To add context for this blog post, I will just mention a couple:
- Compositions are great, but they need more flexibility. For example, you should be able to have conditional logic to define when specific resources need to be created and when they shouldn’t. This is currently being addressed in the Crossplane community.
- Suppose you want to manage a resource not supported by Crossplane providers. In that case, you need to write your own Crossplane Provider, which currently means using KubeBuilder and Go to write a Kubernetes controller.
These limitations made me think about the next project we will evaluate, MetaController, which serves an entirely different purpose but alleviates some of these limitations. But I want to be 100% clear here, I am not saying that you can replace Crossplane with MetaController. Still, I do see in a short team future mechanisms in Crossplane following a similar approach to MetaController to alleviate the pain of these current limitations.
MetaController, let’s not write controllers, just our custom logic
In the case of MetaController, you are also extending Kubernetes, but you are not in charge of writing a fully-fledged Kubernetes controller. With MetaController you are in charge of just writing the logic to define what to do every time a new custom resource is created. The beauty of this approach is that the logic you need to write doesn’t require you to add any dependency to Kubernetes or use any predefined language. You can choose the tools and programming language that you want to write that logic, and this is BIG! It allows every programming language to shine when building Kubernetes integrations. The fact that you don’t need to interact or even worry about interacting with the Kubernetes API makes it simple from a security point of view.
But how does this work? The approach here is to install a generic controller (that’s why it is called MetaController) that you can configure to manage any number of custom resources. MetaController doesn't know how to deal with each custom resource, so it allows you to configure a pointer (using webhooks) to which component will need to be notified when a new resource popup or when a resource is modified.
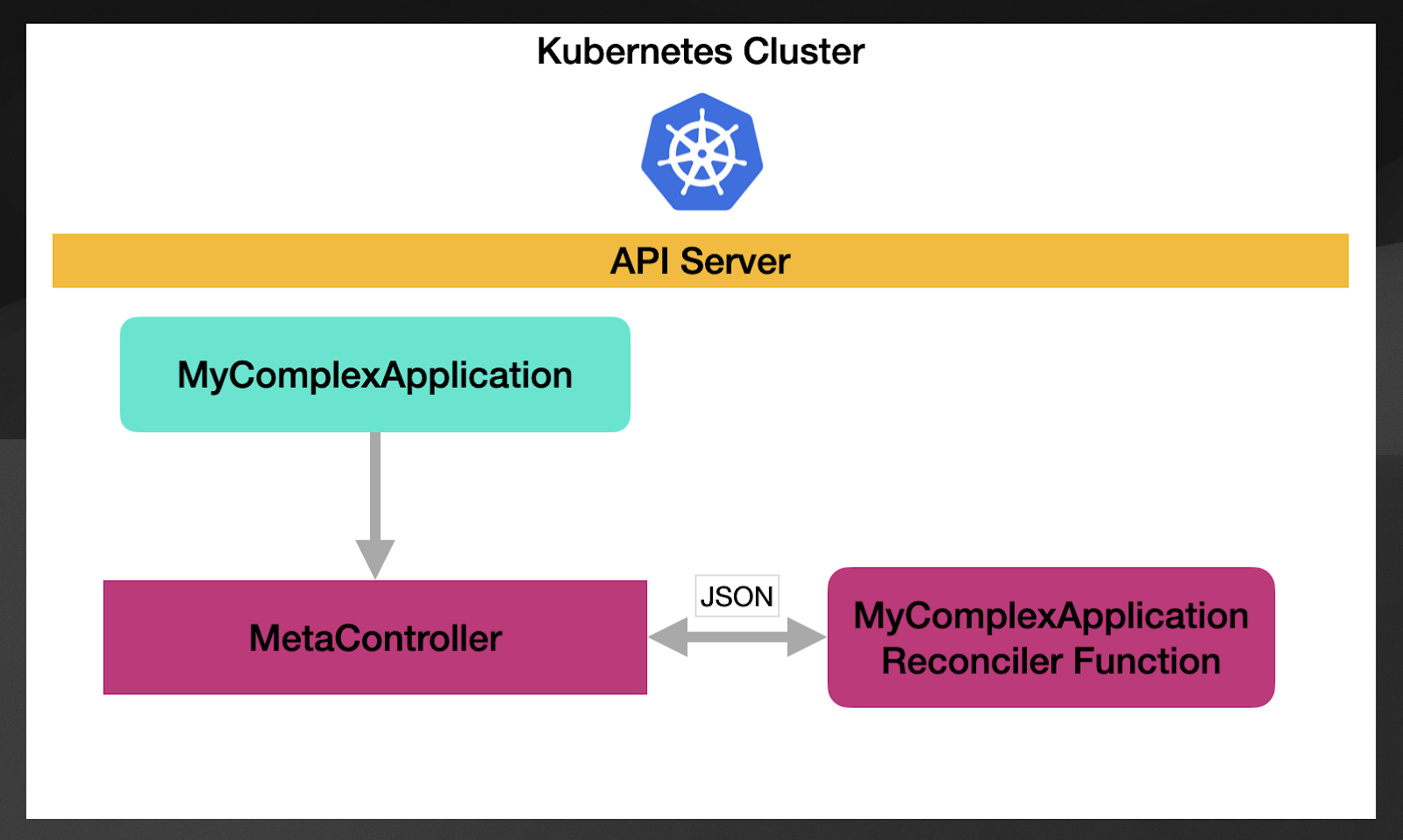
Using a declarative configuration, as we did with Crossplane, we can bind any Kubernetes resource with a reconciler function. The following configuration shows how this works:
apiVersion: metacontroller.k8s.io/v1alpha1
kind: CompositeController
metadata:
name: mycomplexapp-controller
spec:
generateSelector: true
parentResource:
apiVersion:salaboy.com/v1
resource: MyComplexApplication
childResources:
- apiVersion: apps/v1
resource: deployments
hooks:
sync:
webhook:
url: http://mycomplexapp-reconciler.default.svc.cluster.local/You can see that this MetaController CompositeResource binds a parent resource type, in this case, MyComplexApplication, to the reconciler function listening on the URL http://mycomplexapp-reconciler.default.svc.cluster.local/. As you can see, it also defines childResources which lets MetaController know which resources the reconciler function is allowed to create/modify/delete as soon as the parent resource is the owner of those resources. In other words, this configuration is saying, “The reconciler function is allowed to create Deployment resources that will be associated with the MyComplexApplication resource.”
One final and important detail is that the input and output of the reconciler function are just JSON payloads. MetaController will notify the reconciler function with a JSON representation of the resource that needs to be reconciled, and it will expect back a JSON payload containing the status of the resource and a list of children's resources to create or modify. How you parse and produce these payload contents is really up to you. MetaController doesn’t impose anything besides those JSON payload structures.
To sum up, we have extended Kubernetes by defining a CRD and using MetaController to delegate the reconciliation of our custom resources to a reconciler function that can be written in the programming language of your choice.
But as usual, there are some downsides, and to keep it aligned with the topic of this blog post, I would like to focus on the fact that MetaController is not giving you any specialized tools as Crossplane is. Writing reconciliation functions to interact with Cloud Provider APIs using MetaController would be a tremendous job. Usually, these components also need to cover topics like handling credential tokens, API upgrades, and common usage patterns, such as obtaining the credentials and URLs to connect to the resources that were just created. Crossplane already tackles these challenges, but it will benefit to use a similar approach to MetaController for extension points, for example, when you want to support a new API that is not supported out-of-the-box or when you want to provide custom mechanisms to implement more advanced compositions.
One more thing worth clarifying is that while MetaController can be used in setups where multiple clusters are involved, the project was designed with a typical controller in mind, in other words, it focused on a single cluster. While you can have your reconciler functions running outside the cluster where MetaController is installed, you can only add new CompositeControllers where MetaController is installed. The project doesn’t come with any feature to target multiple cluster scenarios.
Next, we will touch on Kratix, a young project that uses CRDs to create Platform APIs but focuses more specifically on covering platform-building scenarios.
Kratix for Platform Building
Finally, Kratix is an interesting project because it focuses on platform building and uses CRDs to create the Platform APIs. In contrast with Crossplane and MetaController, Kratix doesn’t impose any technology or opinions about which tools you want to trigger when new custom resources are created. In the same way, as Crossplane and MetaController work, Kratix allows you to define your CRDs, and then it allows you to define what to do when a new resource is created or modified by creating a Kratix Promise.
Let’s use the same example we used before. If we define MyComplexApplication CRD, you can create a Kratix Promise that links a resource type to a Kratix Pipeline.
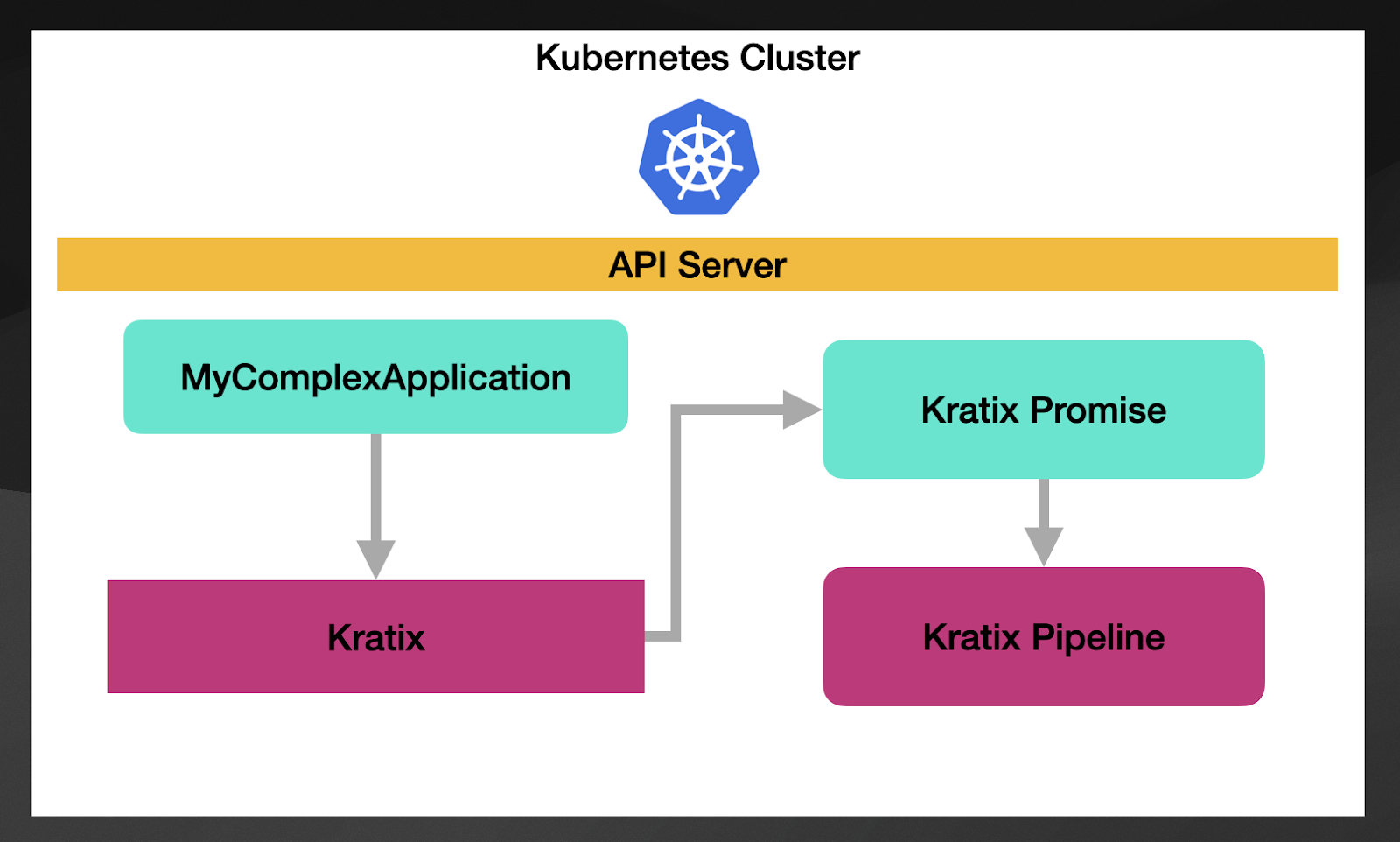
You can find a Promise example here. Where you can see how the CRD is defined alongside to a reference to a Pipeline that is implemented with a container.
apiVersion: platform.kratix.io/v1alpha1
kind: Promise
metadata:
name: mycomplexapp-promise
spec:
clusterSelector:
environment: dev
xaasRequestPipeline:
- salaboy/mycomplexapp-request-pipeline
xaasCrd:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: mycomplexapp.salaboy.com
spec:
group: salaboy.com
scope: Namespaced
names:
plural: mycomplexapps
singular: mycomplexapp
kind: mycomplexapps
...While Kratix is technically more complex to explain, I wanted to highlight here the fact that the xaasRequestPipeline refers to a container image that contains the logic on how to deliver the promise of a new MyComplexApplication resource. I wanted to highlight this point as compared with MetaController, the Kratix team used containers as the interface to deal with resources. This container will receive the resource that triggered the request and can implement the functionality of provisioning all the resources that MyComplexApplication needs by using any tools and programming languages you want.
The exciting thing about this approach is that you can use Crossplane inside your Kratix pipeline, for example, to provision a Kubernetes Cluster or any other Cloud resource.
While Kratix provides this pipeline/container way of linking CRDs to behavior, the Kratix team is also focused on delivering more platform-wide tooling and best practices. I will quickly go over three of what I believe are the most important features this project brings to the ecosystem.
First, I want to mention that Kratix was created to be installed in a Management Cluster (also known as the Platform Cluster). When you look at tools like Crossplane, there is advice on where you should install it or which role Crossplane will take in your platform-building journey, and that is on purpose because Crossplane is very generic.
Kratix, on the other hand, is being built with the primary purpose of helping platform engineering teams to build their platforms, recognizing the needs of these teams and common patterns so they can provide tools to facilitate these tasks.
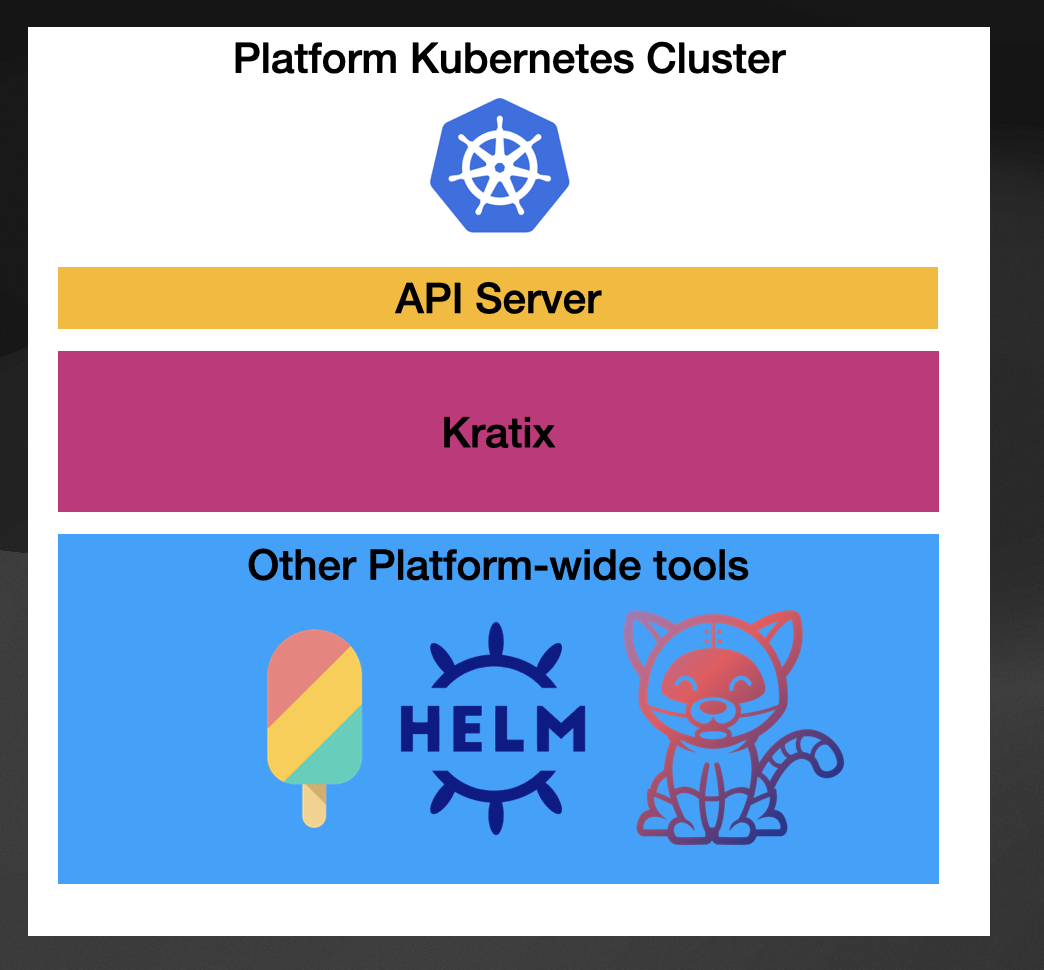
Secondly, Kratix recognizes the multi-cluster nature of platforms, but it doesn’t impose Kubernetes on your platform topologies. You can register any number of Kratix Workers on the Kratix platform. These workers can be Kubernetes Clusters, VMs, or machines that can run the software.
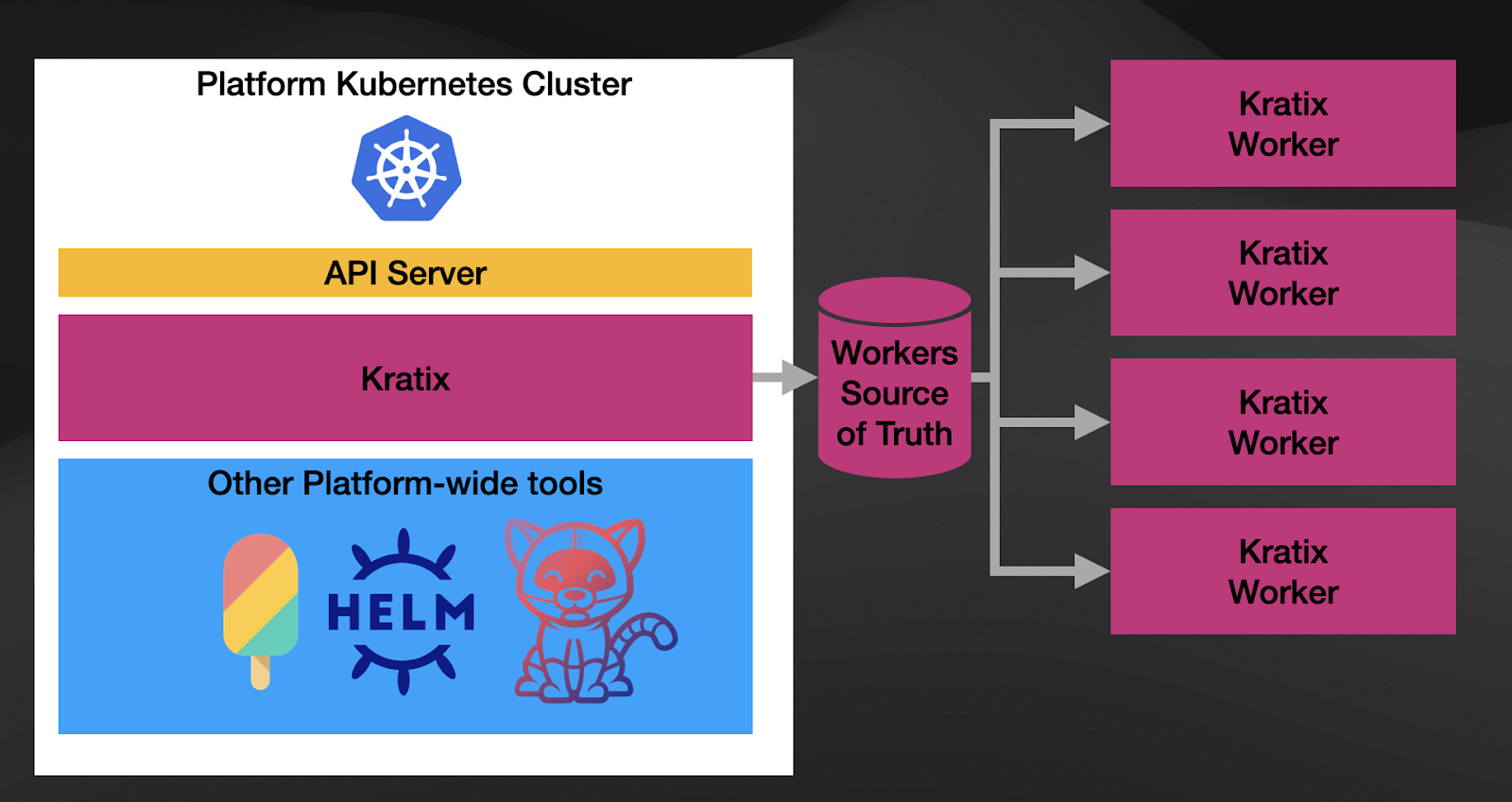
Finally, as you can see in the diagram, these workers are managed using a GitOps workflow out of the box. By following this approach, Kratix can deliver Promises to any of these workers by changing the configurations in the source of truth storage (Git repository or Bucket). By providing this GitOps workflow out of the box, Kratix enables platform teams to focus on delivering value to application development teams instead of spending time figuring out the basics of what the platform will need.
SUM UP
Ok, so in this very long blog post, we have seen 3 different tools that allow you to define Kubernetes CRDs and extend Kubernetes without writing Kubernetes Controllers. That is definitely significant progress, but you might wonder why we want to extend the Kubernetes APIs instead of creating our own Platform APIs outside Kubernetes.
There is nothing wrong with writing your Platform API outside of Kubernetes, but the reasons why the tools we have covered are reusing the Kubernetes APIs are:
- Large ecosystem and adoption: the Kubernetes APIs are widely adopted and supported. Hence if you extend these APIs, you can automatically use all the available tools in the ecosystem to work with your Platform APIs.
- Discoverable: the Kubernetes APIs have a significant advantage. You can register new resources, and by using standard tools like `kubectl` or graphical tools like Backstage, you can discover what resources your Kubernetes Cluster is ready to accept and reconcile.
- Standardize semantics and versioning: using Kubernetes as the base enables new API developers to follow Kubernetes conventions and approaches to evolve their APIs. If you want to build your own Platform APIs you will need to consider these conventions and how to implement them.
- It’s just a tool: nothing is stopping you to build another layer on top of the Kubernetes-based platform APIs, and I would expect teams building management consoles to not hit the Kubernetes APIs directly.
I see many advantages to following this approach to build the core layer of your platforms, and I expect to see more tools building tools with more specialized and opinionated features to compose platforms in this way. I am hyped to see how the platform-building ecosystem grows in the next few years.
In this series's next and final blog post, I will focus on enabling tailored developer experiences on top of these platforms. I believe this is an important topic, as the platforms you build will be as good as the developer experiences they provide. And yes, you got it right “experiences” in the plural. But the tricky thing is identifying which tools can play nicely with how the platform is architected and the target developer experience you want to provide.
Stay tuned, and don’t forget to check out the book I am writing for Manning, covering these topics and more: Continuous Delivery for Kubernetes.