
Knative OSS Diaries – week #32
This week, week 32 and I feel that need some holidays to recharge. So I will be taking a couple of weeks off (offline) to make sure that I get mentally ready for DevoxxUK, KubeCon EU (still on the waiting list) and JBCNConf.
This last week was intense, I had a set of amazing conversations with very smart and interesting people including:
- Local pipelines with Gerhard Lazu, from the Dagger team, was eye opening and it made me think a lot about the content of Chapter 3 of Continuous Delivery for Kubernetes.. More news coming on that front in the next couple of months
- High-scalable event-driven functions with Thomas Vitale, understanding the limitations of different tools that we want to use for our presentation together at Devoxx UK
- Knative Func 1.0 scope and things that we want to get in, you can take a look at the status of the current document. If you want to join the dicussion join the next Working Group meeting on Tuesday.
- The need for a green screen and how OBS is not very user friendly with Whitney Lee in preparation for a Knative Eventing drawing session. Check her previous sessions in her Twitch channel.
Spring Boot / Spring Native upgrade in func
Finally, the spring boot template for the func the project which uses the Cloud Events integration and Spring Cloud Function was updated. This change also disabled Spring Native build, to get started you don't want to produce a native image, this option can be enabled by setting an environment variable to true. The main reason to disable it for the default experience is that it tends to take too long the first time that you build the function, hence it is better to have the option as opt-in by configuration.
https://github.com/knative-sandbox/kn-plugin-func/pull/838
Currently, this template does have the Spring Native dependencies and plugins, which are also adding extra time to the first build as all these dependencies need to be fetched. What do you think? should we comment out all these dependencies and clearly document how to enable Spring Native? or is it ok to spend a little bit of extra time to fetch the dependencies and then by switching a single environment variable you can produce a native build?
CDEvents Initiative
Huge progress is being made by Ishan Khare by building a Knative Serving CDEvents Controller and a Crossplane CDEvents Provider. Each project presents different challenges and uses a different style of controllers and tools to build and package these components.
- Knative Serving CDEvents Controller
- Defining a way to emit the correct events when Knative Services are created, upgraded and published can be achieved by having a Knative style controller which uses the CDEvents Go SDK to emit events to a configurable SINK. Having a separate controller has the advantage of being an opt-in feature that you decide to use when installing Knative.
- This can also be achieved by having existing controller extended to emit this events, without the need to add a new controller. This would require to produce CloudEvents from inside Knative Serving Controller and possible including the CDEvents GO SDK as a dependency.
- Crossplane Provider for CDEvents
- For this first initial milestone, we want to capture from other Crossplane Providers such as (GKE, AWS and AKS) when a Kubernetes Cluster is created, ready and deleted. This requires understanding which providers are installed in a crossplane installation and then listen to generic events that will be provider specific. This in itself is quite a challenge, as providers tends to be scoped to a group of resources related to a CloudProvider.
- It was interesting to see that the sample provider is now using a new tool from Upbound called Build: https://github.com/upbound/build to build and produce the artifacts.
The main goal of having these two controllers emitting events is to integrate them into a flow with Tekton and its experimental CDEvents controller.
It is also really good to see that CDEvents is going into its own Github Org CDEvents.
Building a scalable, function-based game is hard
Building a scalable solution is really hard, and you are always faced with hard choices that will directly impact the application experience. When the aim is to have an application live in front of an unknown amount of users, each architectural choice will come with solutions and problems that you will need to face.
Thomas and I were exploring a very simple idea using Knative Eventing and `func` to build a scalable event-based game where we can plug new levels on demand (a-la Candy Crush). If each function can consume a single event at the time, we will need to be able to store events to correlated them and define if the player is making progress in the level until the goal for that level is reached.
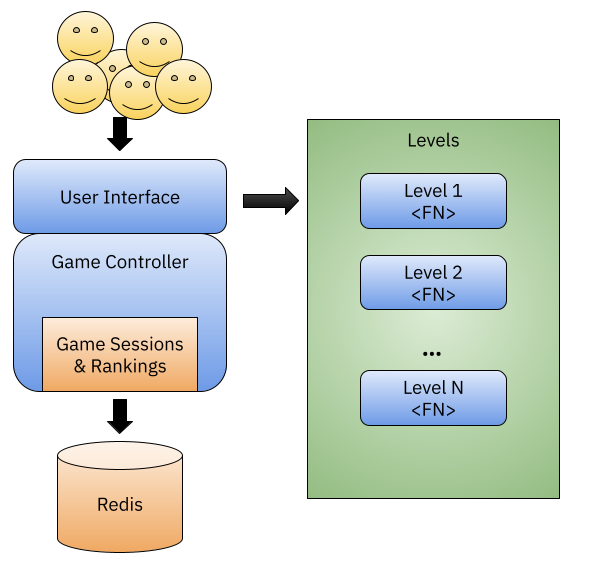
If each function will receive multiple events associated with a single player, the function itself will need to be able to get previous events, do some aggregations and based on that define if the level goal was met or not. If the level goal is met, then the player can move on to the next available level.
Something that is interesting about this kind of scenario, is that with a high load of events, functions will be scaled up and they will all need to have access to the state at the same time. Because of scaling, and because we are not interacting with functions directly, we are using the Knative Broker + Trigger to route events to the function, there is no mechanism that provides some kind of stickiness to the same instance of the function to do some kind of local caching, or to deal with all events for the same player in the same context.
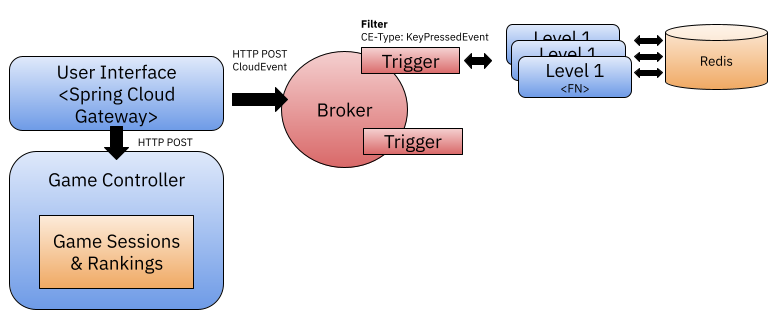
Interestingly enough stickiness to Knative Services has been a requested feature already: https://github.com/knative/serving/issues/8160 and while I understand that in principle functions should be completely stateless and independent from the context, real-life use cases might benefit from some of these mechanisms. While thinking about this particular scenario, I thought that it might be a good idea (only for some extreme cases) to enable stickiness based on a business-key/correlation-key at the trigger level. For example, if the trigger needs to dispatch a CloudEvent, it can inspect the CloudEvent headers (attributes) and use a special attribute to decide to which replica of the function to route this specific event.
It also becomes quite clear pretty early on, that instead of having storage at the function level, you can use the underlying message broker infrastructure to aggregate event data using some domains specific logic and implementation-specific mechanisms. Initially, I wanted to avoid going into that direction to not be too tied to the specific Broker implementation.
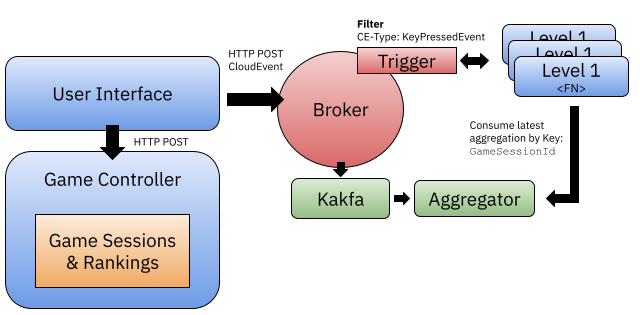
The more we dig into the details, the more this architecture might change, as we want to build something that scale, works but it doesn't go too much into the specific of using Kafka or other message brokers.
See you all when I get back from holiday!