
Event-Driven applications with CloudEvents on Kubernetes
This week I've spent time writing this tutorial and examples that contain the building blocks that I will use to build a larger example. Feedback is highly appreciated. This blog post is replacing the Knative OSS Diaries #26, I will come back with more news about the community initiatives next week.
We are just starting 2022 but it is quite clear that system integrations and Event-Driven applications should rely on CloudEvents. While this is not something new, the CNCF CloudEvent spec has been around for some time now, I can see that more and more projects are relying on the standard to interoperate with other systems or to expose their internal state so other applications can react to them.
This short blog post covers how you can produce and consume CloudEvents in a polyglot setup using Java and Go as examples. While it doesn't really matter if you use Kubernetes or Docker, the scenario evolves showing what changes when you use containers and a container orchestrator from the application's perspective.
For both application's we will be using the CloudEvents SDK's in Java and in Go respectively. Both applications will produce and consume CloudEvents using the HTTP protocol binding. This means that we will be sending HTTP requests from Go and Java and the CloudEvents SDKs will be in charge of encoding our CloudEvent into HTTP requests. Each application will generate its own type of CloudEvent (app-a.MyCloudEvent and app-b.MyCloudEvent) but they will both share the same structure/class for the event payload/body.
You can find all the instructions on how to run a full step-by-step tutorial here: https://github.com/salaboy/from-monolith-to-k8s/blob/master/cloudevents/README.md
CloudEvents in Java and Go
Let's start with Java, I've decided to build the application using the Spring and Spring Boot ecosystem, we can easily get started as Spring Boot provides CloudEvents integration, which will bring the CloudEvents SDK as a transitive dependency. You can find the Java Application using Spring Boot and Spring Native in this repository: https://github.com/salaboy/fmtok8s-java-cloudevents
Because you can follow the tutorial to run the application, I will use this section to highlight some of points, I believe are important, so then we can compare with the Go approach.
For this project, I've chosen to use Spring Native which brings GraalVM binaries into the picture. This allows the application to have a really fast start time, but it does make more complicated the build process and the end result is platform-dependent, in contrast with a more traditional Java application. Because I wanted to go with Spring-Native I needed to take care of a bunch of things that I wasn't expecting:
- Dependencies: Nothing to crazy here, but you need to include the Spring-Native dependency in your project for this approach to work: https://github.com/salaboy/fmtok8s-java-cloudevents/blob/main/pom.xml#L50 It would be nice to have this defaulted for Spring Boot projects moving forward, but it is totally understandble that Spring Native will not fit every use case that we can cover with a more traditional approach. Here you also need to include 3 CloudEvents specific dependencies:
cloudevents-spring,cloudevents-http-basicandcloudevents-json-jackson. - Build process: As with every Spring Boot application, we can use the Spring Boot Maven plugin to start the application locally with
mvn spring-boot:run. For Spring Native to work we need to use Buildpacks which are really good and can be configured using a Maven Plugin (here and here). While this is well documented and easy to use, migrating from a non Spring Native application to a Spring Native application end up not being straight forward as it really depends on which other plugins you have and how they were configured. A nice addition to thespring-bootmaven plugin goals isspring-boot:buildImagewhich produces a container image with the Spring Native applicaiton in it. Important to notice here, I haven't written a Dockerfile, Spring Native and Buildpacks does take care of it. - Consuming and Producing CloudEvents: With Spring Boot you can easily expose REST endpoints by using the @RestController annotation, there are no issues with Spring Native and the Webflux (reactive) stack, hence you can quickly expose two endpoints, one for producing CloudEvents and one for Consuming CloudEvents. On the consumer side, it is really nice to get a CloudEvent object (from the SDK) constructed for us by the Spring Integration (
public ResponseEntity<Void> consumeCloudEvent(@RequestBody CloudEvent cloudEvent)). This doesn't happen out of the box, you need ot make sure to add two codecs that are in charge of reading and writing CloudEvents - Marshalling/Unmarshalling payloads with Jackson: Unfortunately, if you want Spring to parse and automatically create custom objects from the CloudEvents payload you will need reflection, and that is something that Spring Native can't handle very well. There are a lot of libraries which had been refactored to avoid any issues, but Jackson is one of the libraries where you need to give Spring Native hints about which types you will be unmarshalling. Because the CloudEvents that we will be sending to this and the Go application share the same payload, in Java we need to have a Java Class (POJO) to represent this data structure. You can find this class here. Notice the annotation
@JsonClassDescriptionused to hint Jackson about this type so it can automatically unmarshal it when it arrives inside a CloudEvent or when we want to write a CloudEvent and send it via HTTP to another service. - Environment Variables: by default in Spring Boot we have the
SERVER_PORTenvironment variable to define which port the application will use to serve HTTP request. We can read and define defaults for Environment Variables using the@Valueannotation. I used this to being able to specify theSINKurl where the application will send CloudEvents. This allows me to deploy the application in different environments (local, docker, kubernetes, cloud) and configure it accordingly to point to the right service.
Let's switch to Go now. In Go, things are more simple and like in Java, we will need to make some decisions about which frameworks/libraries we want to use to do different things. You can find the Go application here: https://github.com/salaboy/fmtok8s-go-cloudevents. Let's analyze the same points that we analyzed for the Java application:
- Dependencies: compared with Spring, in Go dependencies are kept to the minimum, as there is nothing like Spring, at least not for this setup. I decided to use Go Modules as it seems that the Go community has settled into it and I've just needed to add two dependencies, the CloudEvents SDK and Gorilla Mux which is an HTTP request router.
- Build Process: no plugins or anything weird needed, the old
go run main.gowill do the work here. If you want to containarize the application you can use tools like google/ko, which I did to produce a docker image that you can run. - Consuming and Producing CloudEvents: This was the most shocking part for me, as in Go you need to create and start your webserver, because you start with nothing which is good and bad. I needed to make a decision here and use Gorilla Mux to be able to route requests to different go functions depending on what I wanted to do when different requests arrive to different paths. But it wasn't as simple as I expected, because we also want to allow the CloudEvents SDK to marshal and unmarshal CloudEvents from HTTP Requests we will need to register different kind of handlers depending if we are expecting a CloudEvent or a plain HTTP request. This allowed us to have a CloudEvent struct created from us by the SDK (
func ConsumeCloudEventHandler(ctx context.Context, event cloudevents.Event). We did the same in Spring Boot by registering the Codecs with a Spring configuration. - Marshalling/Unmarshalling payloads: As with Spring, we need to unmarshal the payload into a Go Struct by just using the json library provided out of the box in Go, but no weird stuff here with reflection like in Spring Native. Notice that in Go, instead of having a class I have a struct (MyCloudEventData) which contains the same properties as the class in Java.
- Environment Variables: there are libraries in Go to deal with Environment Variables in a more safe way, doing checks and providing sensible defaults, but I deciced not to add more dependencies to the project. Hence I needed to define two environment variables to match what the Java application was doing
SINKandSERVER_PORT.
The need for Event Routers in Kubernetes
While producing and consuming CloudEvents is the first step and very important for developers building distributed and event-driven applications, routing these events around in a reliable way is not a simple task. Isolating the complexity of the infrastructure required to route events without increasing the complexity of the tools that developers will need to use is key to speed up the delivery of software components and to enable developers to keep their stack of choice simple and independent of the underlying transport protocols (HTTP, AMQP) used to delivery events from one service to another.
If you follow the step-by-step tutorial, you will start by running both services using containers.
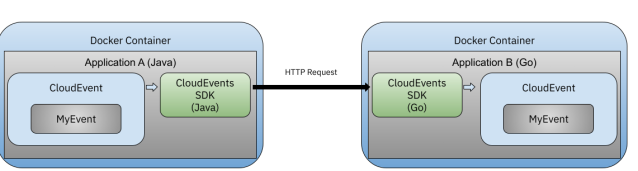
Even when we run these two applications using containers and HTTP requests if you don't want to rely on IP addresses you need to set up a dedicated Docker Network to use the containers name to specify where the event should go. Notice that sending events from one service to another is not really an Event-Driven architecture, as Application B in this case is not reacting to an event that Application A emitted. In this case Application A is explicitly sending an event to Application B.
If we run the same set-up in Kubernetes, HTTP requests can be load-balanced across multiple replicas of Application B. In Kubernetes, at least the networking and scaling capabilities are provided out-of-the-box. By using a Kubernetes Service at least we are decoupling the producer from the consumer instance and Kubernetes is taking care of routing our HTTP requests to an Application B replica.
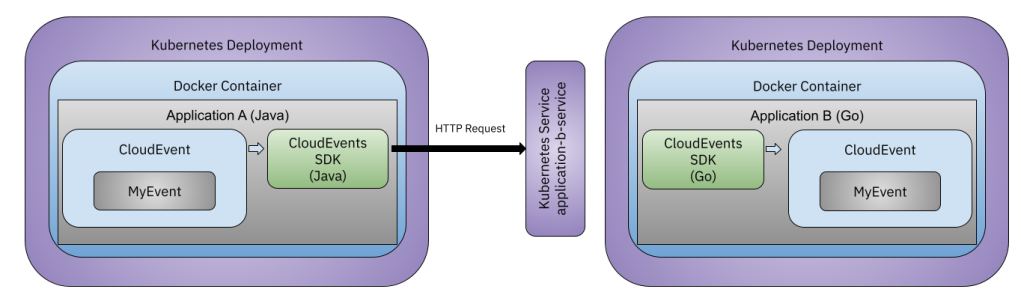
I would recommend you to give it a try, to change the number of replicas and check which replica gets the event.
But if we really want to implement an Event-Driven approach we need to be able to react to events and each service should be able to register interest in only the events that are relevant for them. This is usually achieved with message brokers such as RabbitMQ, Kafka among others or in Cloud Providers by using services such as Google Pub/Sub, Amazon SQS, which can provide async messaging between different services. We are moving away from one service calling another towards a model where services will emit events into a common place without knowing anything about consumers, and consumers can react to these events without knowing when or who produced these events.

The paradigm here is completely different, more than one application can be interested in consuming the same event and because the producer shouldn't need to be aware of the consumers, the event can be placed in the RabbitMQ broker for consumers to pick it up. This also allow consumers not be be running when the event is generated, building resiliency into the system as a whole, as both, producers and consumers can go down and resume at a later point knowing that if they have placed an event into the broker, the event will not be lost.
While this approach has proven to robust and widely used, there are a couple of challenges that developers will face no matter their technology of choice for the message broker:
- All applications need to include a client to connect to the message broker, this adds on dependency and also requires developers to understand how the underlaying technology works and which guarantees it provides to them. They need to learn new APIs and make sure that they update the clients used to connec to the message brokers if the broker itself gets updated.
- Moving away from a request-based approach, which is synchronous in nature to a completely async paradigm requires a mindset change and probably rearchitecting large pieces of your application hence you might face push-backs from developers that would rather keep a more synchronous approach.
- There are no concepts of Producers and Consumers of events in Kubernetes, hence all the interaction between services and components which are producing, consuming and routing events will happen outside of the Kubernetes APIs and resources.
Wouldn't be great to have a way to use message brokers with HTTP, without adding any new dependency to our applications? Wouldn't be great to have an abstraction layers which takes care of defining common patterns for Consumers and Producers of events without pushing us to choose for a single message broker technology? Wouldn't be great to have Producers, Consumers and Event Routers described as Kubernetes resouerces? Welcome Knative Eventing!
Knative Eventing
The last part of the step-by-step tutorial shows how you can still use Kubernetes Services but instead of pointing your services to each other, we rely on a Knative Eventing Broker and Triggers (subscriptions to events). Notice that we not changing the applications in any way, besides the URL where they will send CloudEvents now. Now new dependencies, no new code, no crazy frameworks or weird protocols.
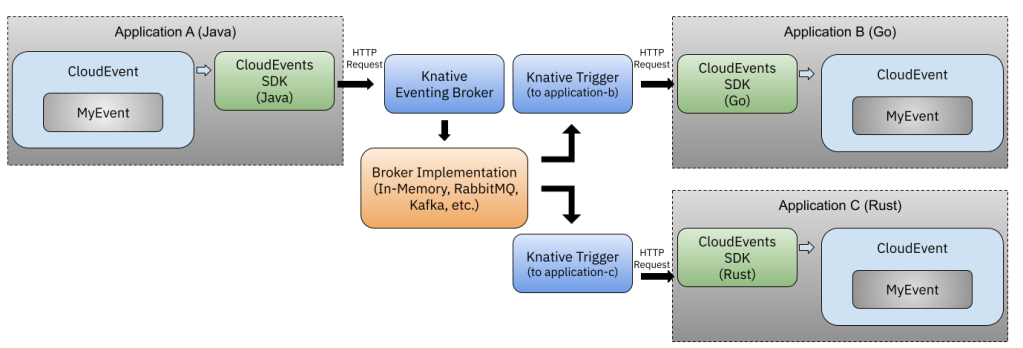
Both Brokers and triggers are Kubernetes resources which you will be creating in the tutorial to route events from these different applications.
apiVersion: eventing.knative.dev/v1 kind: Broker metadata: name: default namespace: default
When you create a Broker you will have an URL to send messages to the Broker using HTTP requests, the Broker implementation will accept the request and create a message to the underlying message broker that you installed.
Then services can register interests in different type of events by creating triggers that can filter events based on the CloudEvent attributes and extensions. For example, the following trigger will only forward CloudEvents with type app-b.MyCloudEvent to the application-a-service.
apiVersion: eventing.knative.dev/v1 kind: Trigger metadata: name: app-a-trigger namespace: default spec: broker: default filter: attributes: type: app-b.MyCloudEvent subscriber: ref: apiVersion: v1 kind: Service name: application-a-service
If you list your Knative Eventing Triggers you will notice that the trigger is not just a passive subscription. Because we have defined a reference to a Kubernetes Service, Knative Eventing will check that the service is present to change the status of the Trigger resource to Ready only if the Service is there.
Sum Up
This was just an introduction to the topic and hopefully with the step-by-step tutorial you can get your hands dirty sending CloudEvents between different services in Kuberntes with Knative Eventing. I strongly recommend you to go into the projects and check the source code, dependencies and how the events are produced and consumed. If you are a Rust/TypeScript/JavaScript/C# fan, would you help me to create another client following the same approach? It will be great to add more languages/frameworks and tools to the comparison and also to check that the CloudEvents SDKs and Knative Eventing Routers are aligned. Are you running in a specific Cloud-Provider (GCP, Amazon, Azure)? it will be great to try their Broker implementations or swap between Kafka and RabbitMQ. Feel free to reach out via Twitter @Salaboy if you have questions or comments, feedback is always appreciated.