
Are You Cloud-Native?

Take 35% off Continuous Delivery for Kubernetes by entering fccsalatino into the discount code box at checkout at manning.com.
Let’s get the definitions out of the way, Cloud-Native is an overloaded term, and although you shouldn’t worry too much about it, it’s essential to understand why this article makes use of concrete tools that run on top of Kubernetes using containers.
A good definition of the term can be found in VMWare site by Joe Beda (Co-Founder, Kubernetes and Principal Engineer, VMware) https://tanzu.vmware.com/cloud-native
“Cloud-Native is structuring teams, culture, and technology to utilize automation and architectures to manage complexity and unlock velocity.”
As you can see, there’s much more than the technology associated with the term Cloud-Native. It has a people and culture angle to it that pushes us to reevaluate how we build software. This article covers technology, but it makes references to practices that can speed up the process of creating and delivering Cloud-Native applications.
On the technical side, Cloud-Native applications are heavily influenced by the “12-factor apps” principles (https://12factor.net) which were defined to use cloud computing infrastructure. These principles were created way before Kubernetes existed and served to establish recommended practices for when building distributed applications. With these principles, you can separate services to be worked by different teams all using the same assumptions on how these services work and interact with each other. These twelve factors are:
- I. Codebase
One codebase tracked in revision control, many deploys - II. Dependencies
Explicitly declare and isolate dependencies - III. Config
Store config in the environment - IV. Backing services
Treat backing services as attached resources - V. Build, release, run
Strictly separate build and run stages - VI. Processes
Execute the app as one or more stateless processes - VII. Port binding
Export services via port binding - VIII. Concurrency
Scale out via the process model - IX. Disposability
Maximize robustness with fast startup and graceful shutdown - X. Dev/prod parity
Keep development, staging, and production as similar as possible - XI. Logs
Treat logs as event streams - XII. Admin processes
Run admin/management tasks as one-off processes
By following these principles, you’re aim is to manage and reduce the complexity of building distributed applications, for example, by scoping a smaller and more focused set of functionalities into what is known as a microservice. These principles guide you to build stateless microservices (VI and VIII) that can be scaled by creating new instances (replicas) of the service to handle more load. By having smaller microservices, you end up having more services for your applications. This forces you to have a clear scope for each microservice, where the source code is going to be stored and versioned (I) and its dependencies (II and IV). Having more moving pieces (microservices), you need to rely on automation to build, test and deploy (V) each service, and having a clear strategy becomes a must from day one. Now you need to manage an entire fleet of running services, instead of one big ship (monolith), which requires you to have visibility on what is going on (XI) and plan accordingly for cases when things go wrong (XII). Finally, to catch production issues early (X), it’s highly recommended to work and regularly performs testing on environments that are as close as possible to your production environment.
The term Cloud-Native is also strongly related to container technologies (such as Docker) as containers by design follow best practices from the “12-factor apps” principles as they were designed with Cloud-Native applications and cloud infrastructures in mind. Once again, you can implement Cloud-Native patterns without using containers. Still, for the sake of simplicity Cloud-Native services, “12-factor apps”, and microservices are all going to be packaged as containers, and these terms are used as synonyms.
If you follow the “12-factor apps” principles, you and your teams will build a set of services that have a different lifecycle and can evolve independently. No matter the size of your teams, you need to organize people and tools around these services.
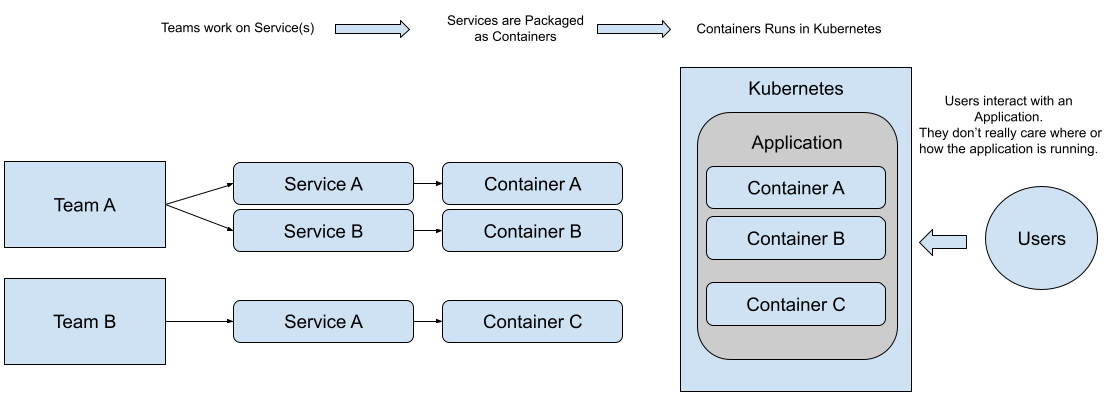
Figure 1 Teams, Services, Containers composing applications for end-users
When you have multiple teams working on different services, you end up with tenths or even hundreds of services. When you’ve three or four containers and a set of computers to run them, it’s possible to decide where these services will run manually, but when the number of services grows and your data center needs to scale, you need to automate this job. This is precisely the job of a container orchestrator, which decides for you based on the size and utilization of your cluster (machines in your datacenter) where your services will run.
The industry already chose Kubernetes to become the de facto standard for containers orchestration. You can find a Kubernetes managed service in every major Cloud-Provider and On-Prem services offered by companies such as Red Hat, VMWare and others.
Kubernetes provides a set of abstractions to deal with a group of computing resources (usually referred to as a cluster, imagine a data center) as a single computer. Dealing with a single computer simplifies the operations as you can rely on Kubernetes to make the right placements of your workloads based on the state of the cluster. Developers can focus on deploying applications, and Kubernetes takes the burden of placing them where it’s more appropriate.
Kubernetes provides a developer and operations friendly declarative REST API to interact with these abstractions. Developers and Operations can interact with different Kubernetes Clusters by using a CLI (command-line interface) called `kubectl` or directly calling the REST APIs exposed by each cluster.
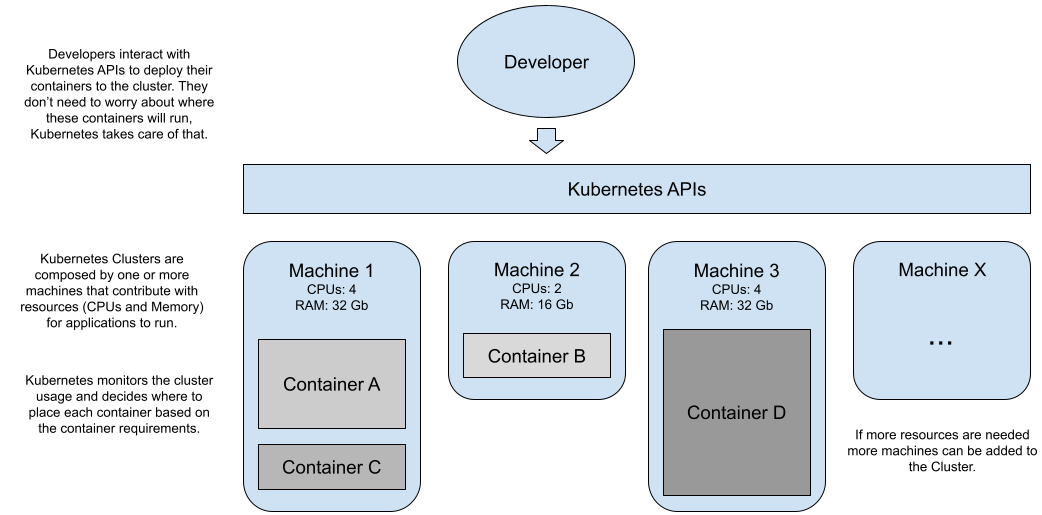
Figure 2 Kubernetes lets you focus on running your services.
Kubernetes is in charge of deciding where your containers run (in which specific machine), based on the cluster utilization and other characteristics that you can tune. Most of the time, as a developer, you’re only interested in having your applications run, not where they run.
Both Kubernetes in Action and Core Kubernetes are highly recommended books if you’re interested in learning how to work with Kubernetes and how Kubernetes works internally.
Challenges of delivering Cloud-Native applications
When working with Kubernetes, containers and twelve-factor applications you quickly notice that a lot is going on. If it’s your first time in such environments, there are loads of challenges to tackle to even understand how pieces fit together.
From the architecture point of view, your (micro)services now rely on other components that aren’t co-located in the same machine. These services need to be configured to understand the environment where they run and these services need to follow certain conventions and best practices to work together.
These services are owned and evolve independently by different teams; collaboration and constant communication are needed when changes that might affect other teams and services are going to happen.
To run each of these services (in Kubernetes) now, you need to take into account creating, building and testing containers and Kubernetes YAML files. It isn’t enough to produce a binary for your application, you now need to consider how your application is containerized, configured and deployed to a Kubernetes cluster.
Sooner or later, you’ll realize that there’s no Application anymore, now you have a set of independent services which are evolving at a different pace.
Without having the right tests in place, you’ll spend weeks (including weekends) trying to understand why one of these services is bringing the whole system down.
Without having the right measurements in place, you’ll never know if a change besides adding a feature is slowing down your entire customer experience or if it’s going to cause some downtime in the future.
It’s also important to understand that for your users it doesn’t matter if you use Kubernetes, Containers or even build Cloud-Native applications; all they look for are new and better applications that help them to solve their problems. To make sure that value to the user is always our true north, we rely on Continuous Delivery practices. Continuous Delivery (CD for short), as presented in the Continuous Delivery Book, is a set of practices that helps teams to deliver valuable software to their users in a reliable and efficient way. CD focuses heavily on automation and measuring our delivery processes, to always keep improving. Explaining all of the practices involved in CD is beyond what we want to cover in this article; for now, I’ll explain the goals behind CD and why you should care about learning and apply CD to your day-to-day software practice. In the following section, we focus on understanding in more detail Continuous Delivery goals and how they relate to Cloud-Native applications.
Continuous Delivery Goals
Delivering valuable software to your customers/users in an efficient way should be your main goal. Although building Cloud-Native applications, these become challenging as you aren’t dealing with a single application; you’re now dealing with complex distributed applications and multiple teams delivering features at different paces.
For the remainder of the article, the following goal of Continuous Delivery is going to be used, to guide the selection of different projects and tools for your teams to use:
From the book Continuous Delivery:
“Goal: Deliver useful, working software to users as quickly as possible
Focus on Reducing cycle time (The time from deciding to make a change to having it available to users)”
This goal definition come from the Continuous Delivery book wrote by Jez Humble and David Farley (2010). The book, on purpose, doesn’t go deep into any technologies besides naming them, and because it was written more than ten years ago, the Cloud and Kubernetes didn’t exist in the way that exists today.
Some significant areas are covered by Humble and Farley’s book which you’ll read about here, such as:
- Deployment pipeline: all the steps needed to create and publish the software artifacts for our application’s services.
- Environment Management: how to create and manage different environments to develop, test, and host the application for our customers/users.
- Release Management: the process to verify and validate new releases for your services.
- Configuration Management: how to manage configuration changes across environments in an efficient and secure way.
Cloud-Native Continuous Delivery aims to be a practical guide where you can experience the concepts described by Humble and Farley in their book first hand, with simple tools and a working example that you can modify to test different aspects of Continuous Delivery.
To benefit (and have some return of investments) from adopting Kubernetes, re-architecting your applications and running your workloads isn’t enough. You can only fully use Kubernetes design principles if your organization delivers more and better software to their users faster.
In such a way, the Cloud-Native Continuous Delivery goal can be stated as follows:
“Deliver useful, working software to users as quickly as possible by organising teams to build and deploy in an automated way Cloud-Native applications that run in cloud-agnostic setup.”
This goal implies multiple teams working on different parts of these Cloud-Native applications that can be deployed to different cloud providers to avoid vendor lock-in. It also means the fact that Cloud-Native applications are more complex than old monoliths, but this inherent complexity also unlocks velocity, scalability and resilience if managed correctly.
Are you doing Continuous Delivery already?
Continuous Delivery is all about speeding up the feedback loop from the moment you release something to your users until the team can act on that feedback and implement the change or new feature requested. To be efficient and reliable high-quality software, you need to automate a big part of this process.
I often hear people stating that they already do Continuous Delivery; hence this section gives a quick overview with some of these points:
- Every change needs to trigger the feedback loop: there are four main things that you need to monitor for changes and verify that these changes aren’t breaking the application:
- Code: if you change source code which is built and run, you need to trigger the build, test and release process for every change
- Configuration: if something in the configuration changes, you need to re-test and make sure that these changes broke nothing.
- Environment: if the environment where you run the application changes, you need to re-test and verify that the application is still behaving as expected. Here’s where you control and monitor which version of the Operating System you are using, which version of Kubernetes is being used in every node of your cluster, etc.
- Data structures: if a data structure changes in your application, you need to verify that the application keeps working as expected, as data represent a valuable asset, every change needs to be correctly verified. This also involves a process for deciding how backward compatible is the change and how the migration between the old and new structure works.
- The feedback loop needs to be fast: the faster the feedback loop is, the quicker you can act on it, and the smaller the changes are. To make the feedback loop faster, most of the verifications need to be automated by applying a Continuous Integration approach. Usually, you find the following kind of tests required to verify these changes:
- Unit Tests: at each project/service level, these tests can run fast (under ten seconds) and verify that the internal logic of the services works. Usually, you avoid contacting databases or external services here, to prevent long-running tests. A developer should run these tests before pushing any changes.
- Integration/Component Tests: these tests take longer as they interact with other components, but verify that these interactions still work. For these tests, components can be mocked, and this article covers “Consumer Contract Testing” to verify that new versions of the services aren’t breaking the application when their interfaces (contracts) change.
- Acceptance Tests: verify that the application is doing what it’s supposed to do from a business perspective. Usually, this is verified at the service level, instead of at the User Interface level, but there are different techniques to cover different angles. These tests are executed on top of the entire application, this requires a whole environment to be created and configured with the version of the service that includes the new change, and it can take more time to run.
- Manual Testing: This is performed by a team which will test the application in an environment similar to production. Ideally, these testers should be testing what the users are going to get. These tests are prolonged, as they require people to go over the application.
- Everything needs to be measured: to make sure that we go in the right direction and you keep delivering high-quality software to your users, you need to track how much time and resources this feedback loop is taking you from start to finish. Here are some key measurements which will help you understand how good you are. Based on the DORA report about the State of DevOps (https://services.google.com/fh/files/misc/state-of-devops-2019.pdf) you can measure:
- How frequent your code deployments are: how often are you deploying new versions to your production environment?
- Lead time from committing changes to deploying your service: how much time does it take you from committing a change to version control to having those changes deployed in your production environment?
- Time to recover from incidents: how much time does it take you to fix a service (or a set of services) which are misbehaving because the issue is reported until the system is again in a stable state?
- Change failure rate: how often do you deploy new versions that cause problems in the production environment?
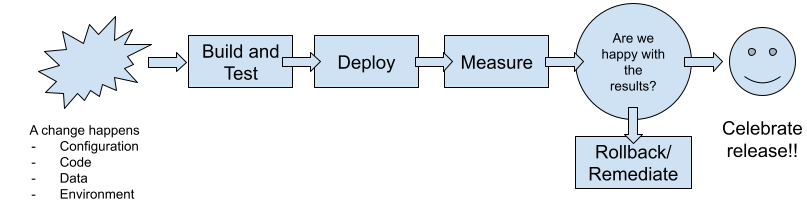
Figure 3 Fast feedback loops help you to accelerate your deliveries
You’re probably doing some of these things already, but unless you measure, it becomes impossible to assert if your changes are useful to your users.
The main objective of this article’s to show how Continuous Delivery can be achieved in a Cloud-Native environment. This helps you deal with the complex nature of distributed teams working on distributed applications. For this exact same reason, an example is needed, and by example, I don’t mean a typical “hello world”.
In order to be convinced that continuous delivery can be achieved for your company or scenario, you need to see an example that you can map almost one-to-one with your daily challenges. To highlight some tools and frameworks we need more than a simple example, hence we use the term “walking skeleton” which represents a fully functional application that contains enough components and functionality to work end-to-end. A “walking skeleton” is supposed to highlight the defined architecture and how components interact with each other. This “walking skeleton” pushes you to define which frameworks, target platform and which tools are you going to use to deliver your software.
That’s all for this article. If you want to learn more, check it out on Manning’s liveBook platform here.