
DDD & knowledge centric methodologies, are they converging?
DDD (Domain Driven Design) is a hot topic today, serving as the main theoretical background for microServices, DDD is used as reference for building complex and distributed systems. On this blog post I wanted to go over some of the main points in DDD to understand how it compares with some other knowledge centric methodologies.
Are you doing DDD?
Before we start, if you are interested in DDD you should read two books DDD and iDDD. I will quote these books heavily, I cannot cover all the important things that are mentioned in these two books, so these two reads are totally recommended.


What is DDD and why do we need to learn about it?
“DDD is a software development approach to create high quality software model design that meets core business objectives.” — from iDDD.
There are two main things that I like about this definition, it mention “core business objectives” and the concept of “software model design”.
The more you read about DDD, the more you realise that it is all about Developers working with Domain Experts in order to make sure that the software that is built represent the Expert's mental models. These models are the center of attention of DDD, meaning that if you want to succeed to apply DDD in your organisation, you need to invest in these models.
Regarding these "models", iDDD mention tons of times the concept of anaemic domain models from M. Fowler, something that we as developers are very used to have in our projects.
If we are going to invest in our models we need to make sure that they reflect the data plus the business logic. Anaemic domain models tend to be a pure reflection on how these models are going to be persisted, we keep them as plain as possible, causing the core domain logic to spread out to our services and some other layers. There are some causes for this, mentioned in iDDD, like for example the JavaBeans specifications and ORM frameworks such as Hibernate, which promote these kind of models which lacks of business logic. We need to make sure to avoid these pitfalls and focus on having a well defined Domain model. From this perspective, "invest in the models" goes first.
Going back to the key points in DDD, part of getting the domain model right is to make sure that we can “Centralise knowledge”, meaning that we need to make sure that Domain Experts and Developers share a common language, a language that make sense to the business.
Another important thing is that DDD is not about technology, it is about business value. Funny enough, that’s the same focus of Domain Experts, their whole job is to produce business value. For that reason DDD just help us to help them to do their job in a better way.
From a methodology perspective, DDD doesn’t propose much, in the sense that relies in Agile techniques to make sure that we keep a continuous discovery process that help us to evolve our domain models to keep up with business changes. From the outcome perspective DDD proposes that the end result is code that we produce, which should reflect the design (iDDD quote “Design is code and code is design”). This means that we should have a small, well-focused and easy to read (for the Domain Experts) domain model represented as code.
In order to implement projects using the DDD approach there are a set of concepts that we will need to understand, I will probably go deeper in further blog posts but for now I will just highlight the ones that I believe that are important for this specific blog post:
- Bounded Context and their relationship with Domains, Sub-Domains and Core domains and their internal Ubiquitous Languages
- Context maps for making sure that we understand how these Bounded Contexts interact with each other
- We need to understand what our Domain Entities, Value Objects and Aggregates are.
- We need to learn about some different architectural approaches and patterns to solve more specific scenarios (EDA, CQRS, Sagas, how to deal with long running processes, etc)
As you can see there is a lot of stuff to take in, and as it is mentioned in books, DDD is about a cultural change in the company. If you ask me, that's the toughest part of all.
There are tons of important lessons in DDD that will help you to build better software. But for me the most important points are:
- Invest in your models
- Centralised Knowledge is key
- Domain Experts must participate in creating the solution
- Common shared language between Devs and Domain Experts
- Clear definition about Bounded Contexts are needed and how these contexts interact with each other
- Continuous discovery and improvement
- Important cultural change required
What do you gain if you follow this approach? You gain pure business value, let’s look at a concrete list of examples:
- The org gains useful model of its own domain
- A refined understanding of the business is developed
- Domain experts contribute to software design
- A better user experience is gained
- Clean boundaries are placed around pure models
- Agile, iterative and continuous improvement is the norm
Now let's look at how these key points and advantages compares with some other approaches/methodologies out there.
Knowledge Engineering
Knowledge Engineering in general is used to contain a set of certain practices and methodologies focused on formalising and automating business knowledge. The term Knowledge Engineering is heavily associated with Expert Systems, and because of that it is considered a sub branch of Artificial Intelligence. But depending on the level of formalisation the definition can be relaxed. For Expert Systems, for example, there is a very well defined mathematical model that will validate and ensure the system behaviour, but most of the times this is not a requirement. In real life, we have more relaxed restrictions on how we prove and test that our software does what it is supposed to do.
I would recommend this book about Knowledge Representation and Reasoning on this topic:

Based on this more relaxed definition we can clearly see that DDD might fits inside the Knowledge Engineering field. With DDD we are refining and automating (executing) the Domain Expertise that we gather inside our Domains and Sub-Domains. We use a shared/common language between our Domain Experts and our technical teams and we collaborate iteratively to maintain and update these definitions.
Inside Knowledge Engineering we will find also Knowledge Management which is the methodology/process to achieve best results. This methodology is iterative and focused on continuous improvement, in other words quite aligned with Agile methodologies, but instead of us focusing on code, Knowledge Management is focused on Knowledge Representations(models).
Other Methodologies
Related with Knowledge Management and Knowledge Engineering we find the BPM methodology that is easy to understand and widely adopted. Decision Management is also quite similar and popular nowadays.
The thing is, that when you start reading about what are all these methodologies main points and motivations you will find an extremely similar list of what we described in the previous DDD section. This list includes: Knowledge centralisation, investing in our models, collaborating and sharing a common language with Domain Experts is key and most importantly a cultural change in the organisation is required for success.
They are all trying to solve the same problem, maybe from different angles, but they are all trying to find out the best way to make sure that whatever software we build we bring the most value to the organisation that is going to use it.
The main big difference between DDD and these other disciplines is the meaning of the term “Model”.
In the next section we will focus on the different types of Models. We need to understand the similarities in order to use them in conjunction to leverage the best of each approach.
Different type of Models, same goals
When we consider these other methodologies we quickly notice that what they describe as models are high level abstractions of the organisation/department behaviour represented using different metaphors. BPM uses the metaphor of the Business Process while Decision Management uses Decision Trees and Decision tables as models. Other disciplines use predictive models such as neural networks as their main way of encoding knowledge (look at PMML).
Once again, it is important to understand that BPM and decision management are not about technology, they are just practices to build better software iteratively.
Note that these Models are usually and correctly labelled as Business Models, to clearly differentiate their intentions.
It is also important to mention that these business models are heavily standardised nowadays. This is a huge advantage because the industry have reach to a consensus about how these models should be defined and executed. Most of these business models are translated into JSON/XML files, which will usually contain information about how to render the model into a graphical representation for non-technical people. Because these diagrams are based on standards BPMN and DMN, for example, the execution semantic of these diagram is also well defined.
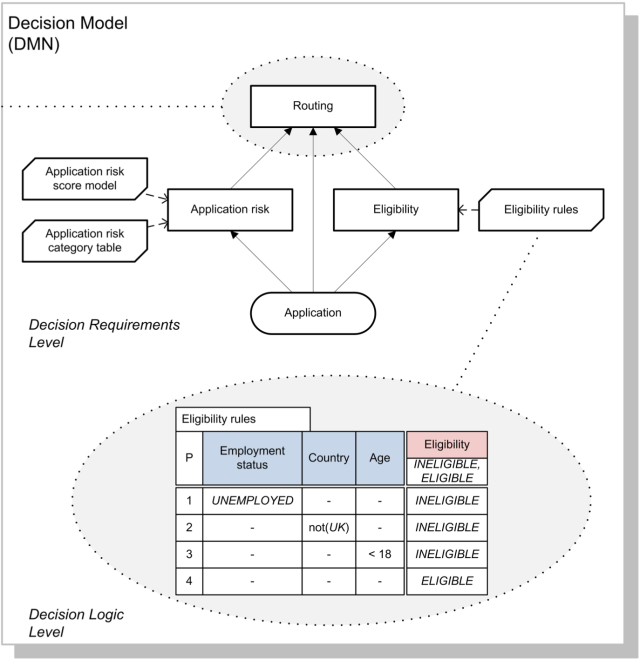
Because Business Models are separate assets, in contrast with DDD, we can deal with these models in different lifecycles from the rest of the applications/services.
These Business Models are usually kept in a separate repository to our application/services source code. This is to enable Domain Experts to collaborate and iteratively improve these business models as needed, without touching the code.
This last point leads us to think about how we can leverage the best of both worlds. On the one hand, we have a rich Java Model, on the other, a Business Model which most of the time will contain references to Domain Entities. This means that Domain Models are not going anywhere. Java Classes representing our Domain entities and providing rich business behaviour is very compatible with the world of Business Models.
Theoretically, we can leverage both worlds by using the right tool for the job. This means that if we have business logic that can be expressed with a high-level business model, we use that in place of a straight forward implementation of that logic inside a set of Java classes. In other words, if we have a very procedural set of steps that needs to be performed my different people and systems, we should use a Business Process model to represent that logic, mostly because our Domain Experts will clearly understand how the process behaves. The same goes for decisions. If we have a set of complicated calculations that needs to be applied based on the value of several properties in your Domain Entities, a Decision Tree might be used to filter all these values and choose the right actions to be executed based on the available data. Again, a Decision Tree can be clearly understood by your Domain Experts, and it will avoid the need for having and maintaining large and complex code, that in my opinion , they will never be able to understand or follow.
In real life, you will notice that Business Models tends to change more frequently than Domain Models. This is mostly because, interactions changes, departments are added and reorganised inside the organisation. New information flows are defined, but the Core Domain model remains the same, sometimes information is added/removed, but the core set of concepts is stable.
From the theoretical perspective, it is beneficial if we can enrich our Domain Models with Business Models so that we can extend the level of participation and collaboration from our Domain Experts. This will now be enabled to propose more and more Business models and to refine them in a different lifecycle from the rest of the applications/services. By refining our Business Models in a separate cycle, we will be generating new requirements for our Domain Models that can be applied by technical people in their technical cycle. Luckly for us most of the knowledge centric tools in the industry such as BPM(Business Process Management) Suites and BRM(Business Rule Management) Suites provides tools to make sure that Knowledge Assets are accessible to consume and well versioned.
Unfortunately, from a technical and architectural standpoint, there are some issues that we will need to sort out and align to make these Business Models play nice in our modern environments. Remember that these business models will be executed, most of the time by a generic runtime also known as Process Engine or Rule Engine, depending on the model and most of these engines were not designed with distributed environments in mind. On my next blog post I will be covering the technical implications of what is being proposed in this post.
Conclusions
This was a long post, starting with DDD and comparing it with some other practices that share similar goals, benefits and motivations. It is a long post because I wanted to make sure that I cover the most important similarities between these approaches. In my opinion these methodologies are theoretically converging and I believe they are all relatively well aligned.
What do you think? Did I missed any big difference/similarity? I look forward to your thoughts, questions, comments, suggestions and contributions.
My next blog post will cover the technical implications of using these methodologies together and how the technologies behind these methodologies can be aligned to survive modern environments.